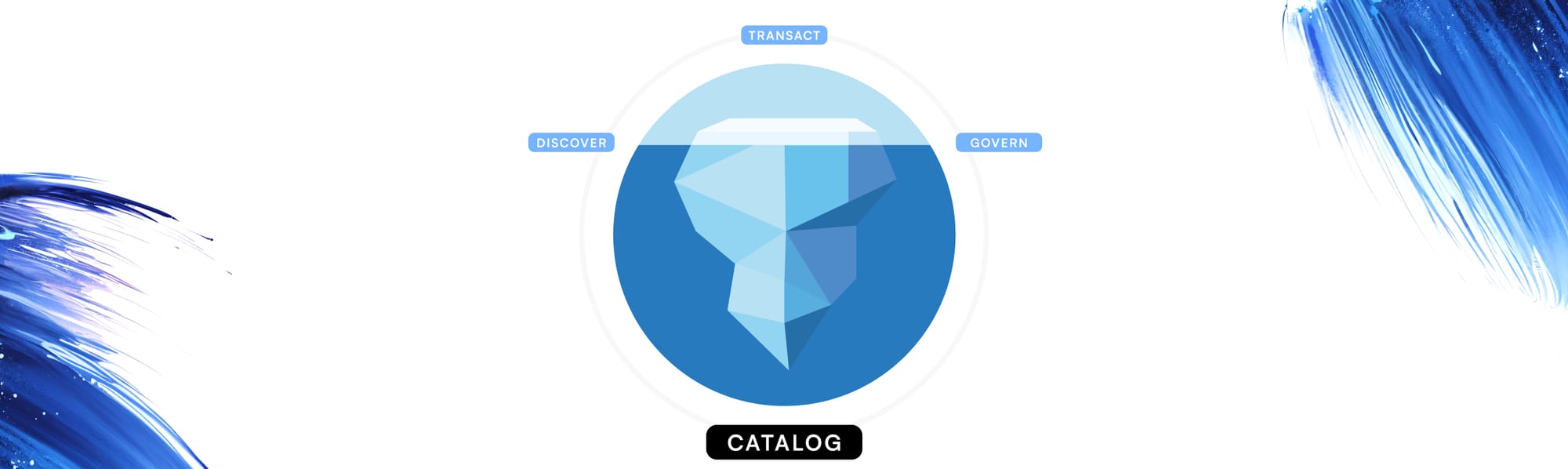
发现、交易、管理?解读冰山目录 API 标准的真正范围。

在数据工程领域,开放标准是构建可互操作、可演进且非专有系统的基础。Apache Iceberg是一种开放表格式,就是一个很好的例子。除了计算能力之外,Iceberg 还为数据湖带来了结构化和可靠性。当与 MinIO AIStor 等高性能对象存储结合使用时,Iceberg 为创建下一代高性能、经济高效且可扩展的架构开辟了新的途径。
然而,这个强大的表格格式标准只是解决方案的一部分。应用程序和引擎如何发现、管理这些表的元数据并与之交互,也需要一种通用语言。这种认识催生了Iceberg Catalog API——一项由社区驱动的标准化这些交互的工作。但这个标准究竟定义了什么?它对使用 Iceberg 进行构建的开发者有何影响?
值得称赞的努力:Iceberg 社区和 Catalog API 标准化
Apache Iceberg 社区推动制定标准 Catalog API是意义重大的一步。此类标准化工作至关重要,因为它们将直接转化为切实的效益:引擎和工具可以更顺畅地连接到各种目录实现,降低锁定特定目录服务的风险,并且客户端和服务器端的开发都可以根据标准规范得到简化。这种协作方式增强了整个 Iceberg 生态系统。有了这个标准化基础,人们可能会好奇,它与通常与通用数据目录相关的功能集相比有何不同。
现代数据目录:无限可能
当开发人员听到“数据目录”时,通常会想到一系列广泛的功能。现代的综合数据目录通常旨在提供强大的数据发现、丰富的技术和业务元数据管理、集成数据治理(包括安全策略和像 RBAC 这样的细粒度访问控制)、端到端数据沿袭跟踪、数据质量洞察以及详细的审计跟踪。它们通常被设想为理解和管理组织数据资产的中心枢纽。那么,专注的 Iceberg Catalog API 标准与这一广阔的愿景有何关联?
Iceberg Catalog API 标准:聚焦核心需求
将通用数据目录中的丰富功能与 Apache Iceberg Catalog API标准进行对比,可以发现其刻意的侧重点。Iceberg API 标准并未试图标准化所有可能的编目功能,而是专注于表互操作性和状态管理所必需的基本操作。这种精心设计的范围确保了其精简且易于广泛采用的接口。
这种方法符合 Minio 的基本工程原则:简单即可扩展。通过专注于必要的、定义明确的功能、系统和标准,我们可以实现更高的稳健性、更佳的性能和更易采用性,同时避免过度复杂的陷阱。
理解这个精确的焦点至关重要,因此让我们从表格的位置开始,检查一下 Iceberg Catalog 要求的核心功能。
标准化表格发现:核心要求
Iceberg Catalog API 的主要标准化功能是表发现。Iceberg 表驻留在对象存储中,这些对象存储可能规模庞大且复杂。Catalog API 标准通过定义如何将表名称解析为指针(通常是其当前根元数据文件的路径,例如 vN.metadata.json),提供了这些表的“映射”。此文件是任何引擎理解表的模式、分区、快照历史记录和当前状态的入口点。诸如 loadTable、tableExists 和 listTables 之类的标准操作确保任何与 Iceberg 兼容的工具都能可靠地定位和解释由兼容 Catalog 管理的表。Catalog 在此处的指定作用并非保存所有元数据,而是可靠地提供当前指针。一旦表被发现,Iceberg 如何处理其修改?
Iceberg Transactions:Catalog API 的关键作用
除了数据发现之外,Iceberg Catalog API 对于实现 Iceberg 标志性的ACID(原子性、一致性、隔离性、持久性)事务功能也至关重要。这些特性为数据湖操作带来了可靠性。Iceberg Catalog 通过其原子提交操作的定义来支持这些保证。当对单个表进行更改(例如,追加、更新或架构更改)时,Iceberg Catalog 会定义如何以事务方式提交这些更改。这通常涉及向 REST 端点/v1/{prefix}/namespaces/{ns}/tables/{table}(或其编程等效项,如 t.commitTable())发送 POST 请求,其中 Catalog 会以原子方式将表的元数据指针从旧的根元数据更新为新的根元数据。这种原子性至关重要。
此外,Iceberg Catalog 还为需要跨多表原子性的场景指定了专用的多表事务提交 API(例如,POST /v1/{prefix}/transactions/commit或其编程等效函数,如t.commitTransaction())。在所有这些提交操作中,Iceberg Catalog 规定的基本原则是 Catalog 对元数据指针进行原子更新,以确保数据完整性。既然发现和事务显然在其管辖范围内,那么 Iceberg Catalog 如何管理对这些表的访问呢?
治理“差距”:Iceberg目录有意不明之处
虽然 Iceberg Catalog API 标准为表发现和事务更新提供了强大的机制,但开发人员同样需要了解它未能全面解决的问题:数据治理。当前 API 标准并未明确定义细粒度的基于角色的访问控制 (RBAC)、数据访问的详细审计日志记录、数据沿袭或特定安全策略的实施等功能。Iceberg Catalog 专注于表结构和状态管理机制,而将综合治理模型的实现主要留给特定的目录服务或更高级别的工具。这种有意的省略允许灵活性以及与各种企业安全框架的集成。那么,如果 Iceberg Catalog 没有规定这些治理功能,那么在实践中如何满足这些关键需求呢?
弥合差距:综合治理专业目录
Iceberg Catalog API 标准中缺乏规定的治理框架,这意味着开发人员和组织必须寻求特定的目录实现或外部工具来满足这些要求。许多与 Iceberg 兼容的目录解决方案(例如Apache Polaris、Nessie、Gravitano等)都基于 Iceberg Catalog API 构建,提供了增值治理层。这些扩展通常包含用于管理权限、角色和审计的 API 和机制,并根据其特定架构进行定制。因此,虽然 Iceberg 确保了表操作的核心互操作性,但要实现强大的数据治理,就需要选择明确提供高级治理功能或与专用治理平台集成的目录服务。这种区别为所有使用 Iceberg 的团队提供了一些关键要点。
性能考虑
在优化 Iceberg 数据湖时,从各个角度考虑性能至关重要。虽然 Iceberg 目录负责管理数据发现和事务,但频繁的提交可能会导致目录服务过载。对于大多数操作(例如查询、数据提取和压缩),性能主要取决于底层对象存储。
Iceberg 的架构包含大量数据文件和多层元数据文件(例如表元数据、清单列表和清单文件),因此快速高效地访问存储层至关重要。低延迟的元数据查找和高吞吐量的数据扫描确保您的数据湖能够快速响应并有效扩展。
这凸显了像 MinIO AIStor 这样的高性能对象存储解决方案的重要性。AIStor 专为高要求工作负载而设计,提供卓越的吞吐量和低延迟,以适应 Iceberg 多样化的 I/O 模式——从快速访问大量小型元数据文件到流式传输大型数据文件。通过优化对象存储层,MinIO AIStor 使您的 Iceberg 数据湖能够实现其性能目标,有效支持最密集的分析和 AI/ML 应用程序。
Iceberg Catalog 在发现、交易和治理方面的范围——已澄清
那么,当我们提出这个问题:发现、交易、治理?Iceberg Catalog API 标准真正规定了什么?本次探索旨在为开发人员和架构师揭示其确切的范围。结论很明确:
对于数据发现,Iceberg 提供了一个强大且必不可少的框架。它规定了 Iceberg 表必须能够被任何兼容引擎一致地注册、查找和理解的机制,从而确保您的数据始终可在对象存储中找到。
对于事务而言,Iceberg Catalog API 至关重要。它定义了支撑 Iceberg 可靠性的原子提交操作,从而实现安全、并发的修改以及数据的一致性视图。
然而,Iceberg Catalog 目前在全面治理方面划定了明确的界限,涵盖了细粒度的访问控制、详细的审计和总体安全策略。它并没有规定这些功能,而是将其实现留给具体的目录解决方案或辅助治理工具。
解读 Iceberg Catalog 的真正范围,关键在于:它为发现表和执行可靠事务提供了一个强大且通用的基础。然而,为了实现强大的治理,您的技术策略必须超越简单的标准,充分利用所选目录实现的扩展功能,或集成专用的治理系统。这种清晰的思路使您能够根据组织的需求,设计和实施基于 Iceberg 的数据平台,这些平台功能强大、可互操作、安全可靠且易于管理。