针对Apache Spark将MinIO与AWS S3进行基准测试


Apache Spark是用于分布式计算的框架。它提供了跨群集中的多台计算机分布数据并对其执行计算的最佳机制之一。
Spark通过构造称为RDD(弹性分布式数据集)的数据结构来实现这一目标。RDD允许将数据分为不同的块,并彼此独立地进行处理。然后可以将各个大块合并以创建最终结果。当数据提供给Spark时,它将自动从中构造这些数据结构。这使程序员可以编写应用程序逻辑并从Spark的并行性中获益,而无需付出任何额外的努力。
当Spark将RDD划分为独立的块时,每个块都与其他每个块并行地进行加载,处理和修改。这导致到存储后端的大量连接,然后是按比例通过网络传输大量数据。基础存储的性能对于获得Spark提供的好处至关重要。
本文讨论了MinIO作为Spark的存储后端的性能,该性能是在基准测试工作负载-TPC-H™基准测试的巨大压力下进行评估的。
TPC-H™基准
当在其上强加模式时,提供给Spark的数据最好并行化。为了测试基础存储的限制,我们选择了具有一致架构的基准。TPC-H基准基于8个相互关联的数据集。数据集的大小基于比例因子。我们将缩放因子设置为1000,这将生成1TB的数据集。
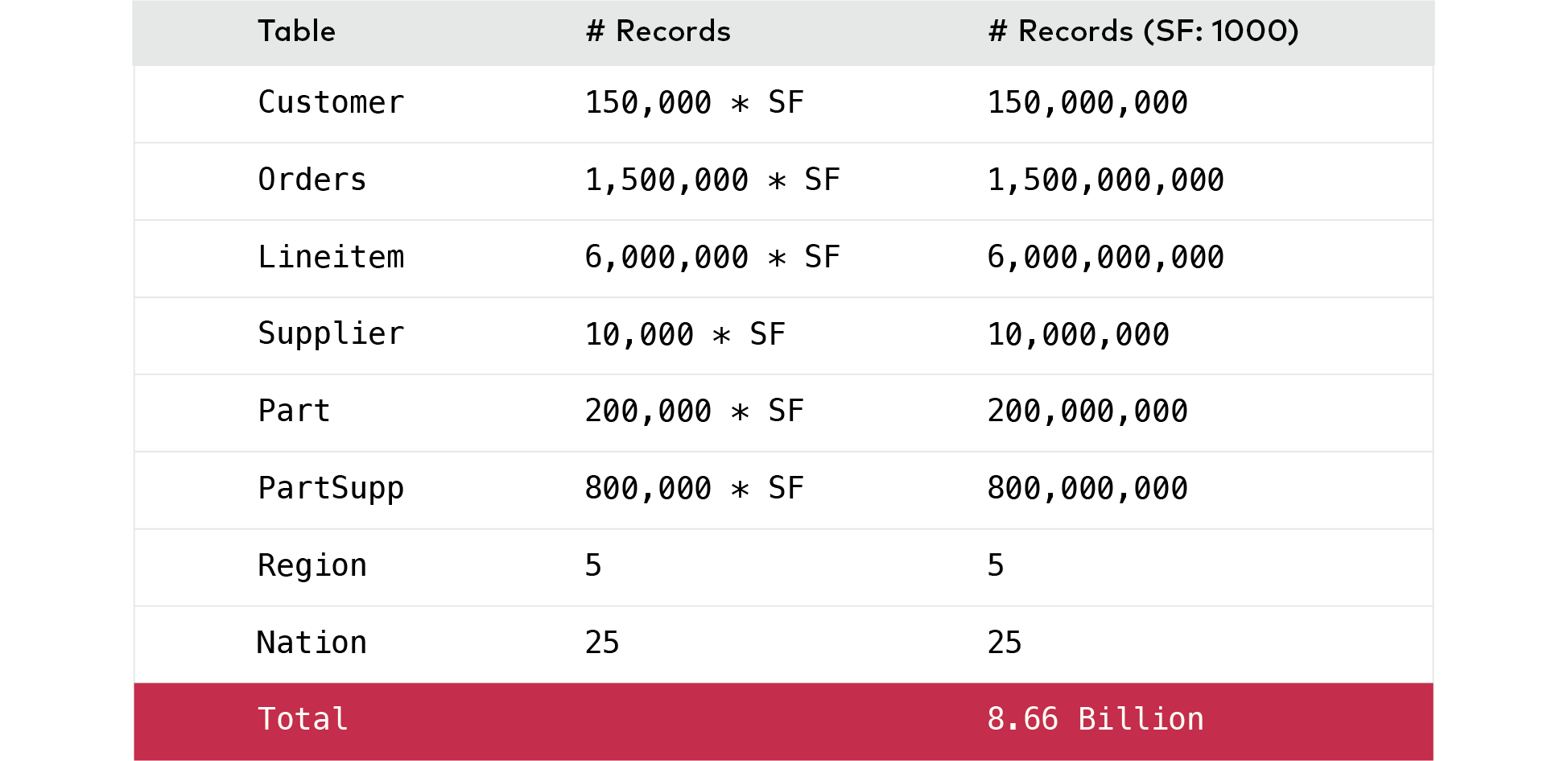
已生成1TB数据集,并以ORC(最佳行列)格式进行格式化,并存储在MinIO存储桶中。转换为这种格式会自动压缩数据,从而将数据大小缩小到273 GB。
Spark MinIO架构
数据集的庞大规模需要一个大型集群才能有效处理此规模。我们在AWS上选择了8个高性能,计算优化实例(c5n.18xlarge)节点来运行Spark。我们为MinIO选择了8个高性能,存储优化实例的高性能(13en.24xlarge)节点。这些实例都连接到100 Gbe网络链接。
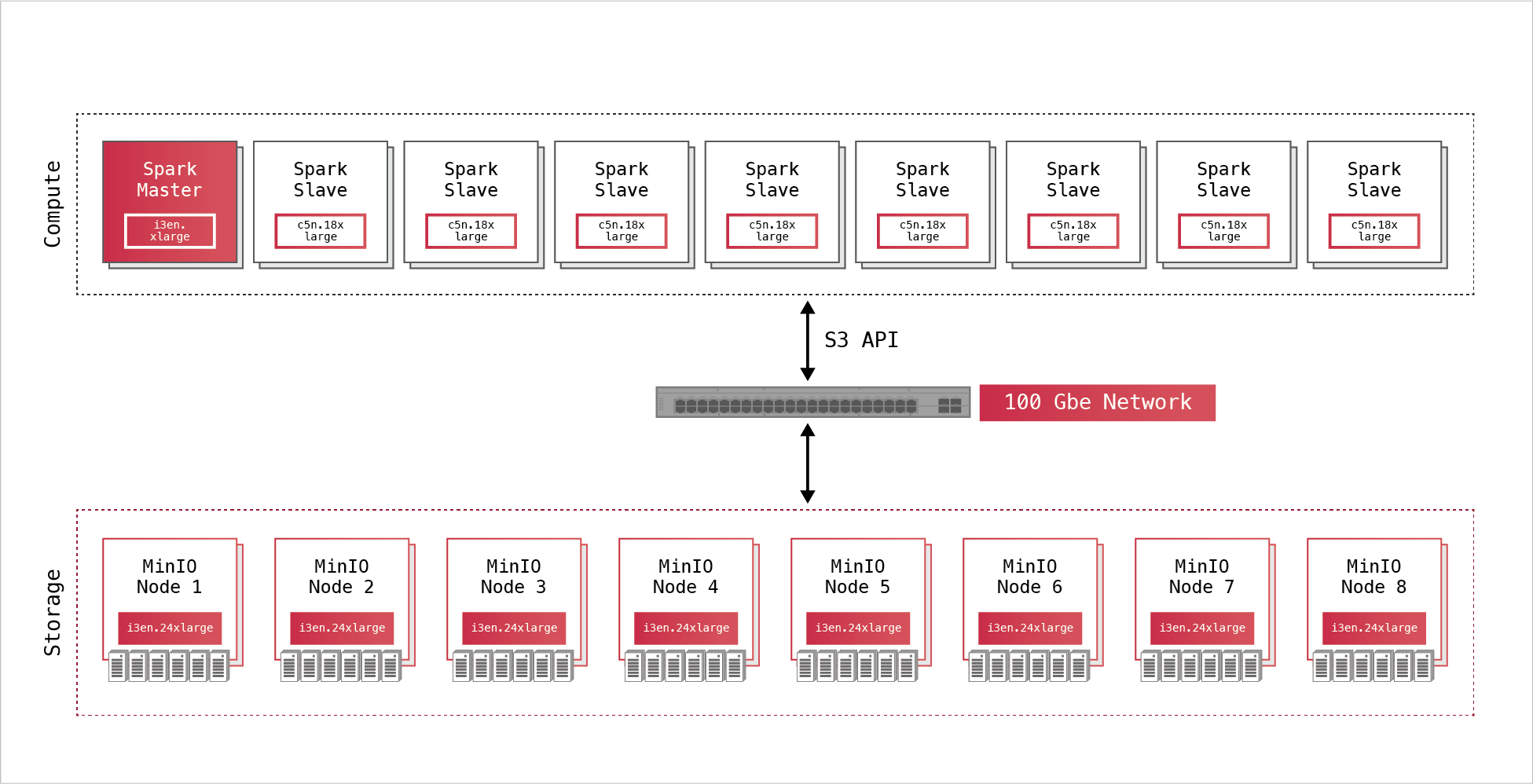
下表详细说明了运行此体系结构的硬件。

火花设置
Spark经过优化,可以根据需要利用与MinIO的尽可能多的连接。这是通过设置以下参数来实现的

此外,我们发现以下设置可带来最佳查询性能

基准结果
下面列出了22个TPC-H™查询中每个查询所花费的时间:
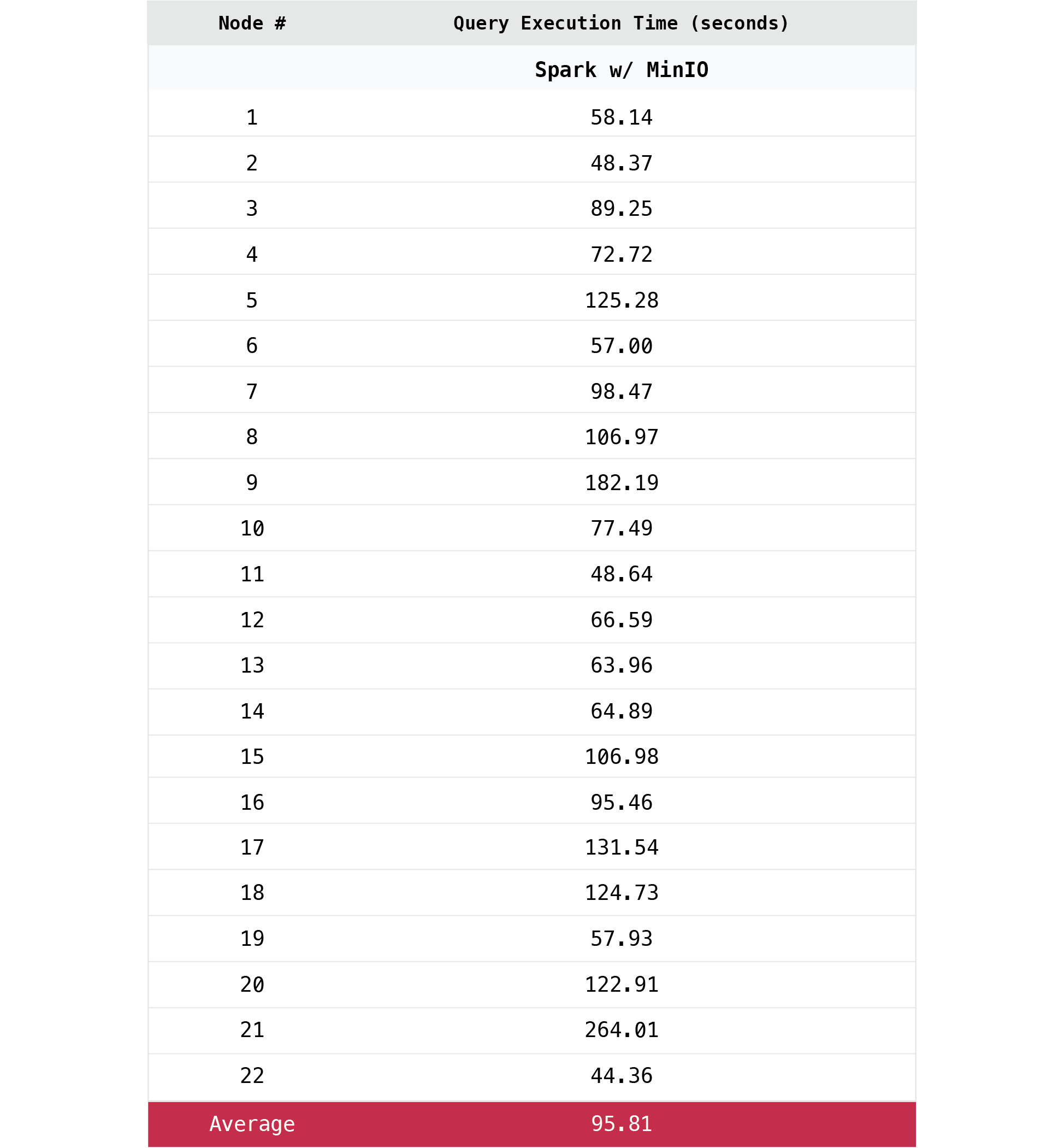
总结以上结果的图表如下所示:

将MinIO与Amazon S3进行比较
使用相同的Apache Spark硬件,针对存储在Amazon S3中的数据运行了相同的基准测试。应该注意的是,MinIO严格一致,而Amazon S3仅最终一致。性能基本相同,有些查询比MinIO慢,而另一些查询比MinIO快,总体上支持MinIO。下图总结了查询时间比较MinIO和S3的Apache Spark工作负载的图表:

在比较中我们发现,无论在总体还是在大多数查询中,MinIO都优于AWS。更重要的是,两者都提供了以前认为超出对象存储功能的性能水平。现在,对象存储的固有优势(可伸缩性,弹性,成本)可以与私有云环境中大规模,高性能,数据密集型工作负载的出色性能相结合。
如有任何疑问,请通过sales@minio.org.cn与我联系,或在页面底部填写技术请求表。