使用由Presto,R和S3 Select功能提供支持的MinIO构建本地ML生态系统

抽象:
任何数字化旅程中的主要挑战之一是采用机器学习技术。鉴于工具和框架的爆炸式增长,可能很难知道从哪里开始,什么选择会阻止其他选择。企业希望针对可扩展性,可维护性,安全性和成本进行共同优化。
本文旨在使企业能够开始使用ML或AI,从而走向未来的增长。这篇文章假定您对Java有一定的了解。我们将一起进行一些代码开发,一些集成工作和一些配置。
在整个本文中,我们将与Hadoop进行比较和对比-了解为什么不需要这种级别的复杂性和可维护性。明确地说,我并不反对Hadoop,我喜欢Hadoop,但是有更好,更简单,更现代的方法来实现企业级分析性能。这些更现代的方法可以减轻团队在重新平衡文件系统,保持擦除编码,对外围工具(例如Apache Ranger,Apache Sentry等)的需求和了解方面所需要的繁琐的周末时间,以提高外围设备的安全性,等等。等等。对于元数据管理,您需要从其他一些工具(例如Apache Atlas)寻求帮助。
您是否曾经看过世界上任何稳定的数据库,其元数据位于另一个数据库中?我不太确定,为什么Hive如此设计。您需要将一个外部数据库配置为您的Hive元存储—可以是Derby或MySQL。如果您的数据在HDFS中丢失,那么大型metastore会保留!让我们对所有这些烦恼说“不”,让我们尝试将元数据与数据存储在一起,并避免在我们建议的ML平台中安装Hadoop或Hive。是的,我们将使用Hive,仅作为接口来投影数据以及定义的关系和元组(对于外行来说,这些是表和行)。
我们将对本文的内容进行如下划分

1. MinIO设置
我不会花时间在上面,因为MinIO是世界上增长最快的本地对象存储系统的原因之一是,它在任何数量的配置中都非常易于安装和运行 。MinIO稳定,可扩展,容错,安全且可持续。您不为MinIO做磁盘平衡:)。您无需担心擦除编码或安全性-这些功能内置了密钥和机密,并且通过组合适当的ACL,您可以拥有一个强大的系统。MinIO完全符合AWS S3 API。
对于MinIO的新手,我建议我另外两篇文章,第1部分和第2部分,详细介绍该技术。

如果尚未安装,请下载正确的下载文件,然后按照快速入门指南进行操作。
这是第一个Hadoop比较/对比时刻。您想升级基于Hadoop的生态系统时,您的组织花费或打算花费什么时间?几个月?可能假设一切顺利。MinIO —即使对于peta / exascale基础架构也要花费几分钟。
看,当我启动MinIO时发生了什么?我有一个旧副本。更新到最新版本并开始工作不到一分钟。

现在,您可以按照以下准则启动服务器:

您可以使用MinIOClient(mc)或S3CMD创建存储桶并使用MinIO。在我之前的文章中,我使用了“ mc”。在这里,我使用s3cmd来演示MinIO的灵活性。让我们使用s3cmd创建一个名为“ mldata”的新存储桶。不要忘记使用上面屏幕上的MinIO服务器详细信息在本地计算机中创建.s3cfg文件。

现在创建一个目录,并通过列出来确保它存在:

在本文的后面,我们将使用文件进行机器学习,特别是用于决策树。我们不会在ML上做任何解释,因为有很多有关机器学习的文档。
我正在使用过去的篮球统计数据进行训练,以预测未来的比赛将是“胜利”(结果是)还是“损失”(结果否)。
这是文件的快照。出于演示目的,我们使用一个小文件。在理想情况下,这可能是数以亿计的元组。

下一步是将这些数据放入我们的存储桶中。为了轻松创建表,我们可以跳过标题行,并将CSV文件称为input.csv。像sed这样的Unix小命令将在这里为我们提供帮助。

您可以删除此数据,因为我们将在本文后面使用Presto从MySQL动态创建表。
2. Presto设定
我们接下来要做的就是使用Presto。首先,请转到Presto的GitHub页面,并将以下文件下载到您的系统中。
我将这些文件放在名为“ MinIOlake”的目录中。将上面的服务器(1)提取到该文件夹中。有很好的说明这里跟随。步骤如下所示:

您将需要三个配置文件,以及一个在新目录“ etc”中名为“ catalog”的目录,该目录必须在提取的服务器文件夹中创建。步骤和文件如下所示。

3.配置Presto以使用文件元存储和S3Select
现在好了。我们现在将目录目录保留为空。那是Presto需要所有连接器的地方。您可以配置Hive连接器并连接到MinIO,这是我在第2部分中介绍的内容。要使用Hive Metastore,Hive必须正在运行并且要启动Metastore服务。我们从来没有机会启用S3Select来启用对基础MinIO的下推谓词。现在,该方法已成为传统:)。我们将对架构进行改造,以适应最新和最佳的架构。让我们从在目录目录中写入MinIO.properties文件开始,以合并文件metastore和S3Select。干得好:

以上配置是本文最重要的部分。最好注意标记为1的两行和标记为2的最后一行。其他行是无关紧要的。
在第1行中,我们使用了Presto中的hive-hadoop2连接器,但是我们说使用MinIO S3存储桶(在步骤1中创建)代替了传统的基于节俭的Hive Metastore。这样,您无需在ML或数据生态系统中安装任何Hadoop或Hive的痕迹。
在第二部分中,我们在Presto中启用S3Select。MinIO只需一行代码即可处理下推谓词请求。如果未启用此功能,则所有数据都将流至Presto,包括过滤,这会对查询的性能产生负面影响,尤其是当查询具有条件并从存储桶中存储的多个表进行联接时。
关闭文件。现在您可以启动Presto服务器。我假设您的MinIO服务器正在运行。通过从服务器目录发出以下命令来启动Presto。

现在,我们已经创建了同类最佳的数据湖。
接下来,我们将创建一个表,指向我们的文件“ input.csv”,该表存在于步骤1中创建的“ mldata”存储桶中。我们将使用Presto CLI(命令行界面,我们已经在“ MinIOlake”目录)。输入以下命令以创建表。在这里,我假设我们在MYSQL中的表位于名为“游戏”的架构内。

(使用标准SQL从前面讨论的有关篮球比赛统计数据中创建表),我们将使用Presto的CTAS(创建表为…)命令在MinIO中创建等效表。这突显了Presto从现有数据库中获取数据并将其迁移到MinIO的强大功能。可以这样完成:

使用现在在S3:// mldata中的表,我们准备好进行下一步。注意上面的表名-MinIO.games.gamestats,这意味着,我们具有连接器MinIO(指向S3://,MinIO存储),一个名为“ games”的架构,并且在该架构中有一个名为“ gamestats”的表格。该元存储显然位于MinIO存储桶“ mldata”中。
绝对没有Hive Metastore,也没有Hadoop,因此也没有从外部启动的Metastore服务。
最后,在Presto中运行以下命令,然后查看输出
从MinIO.games.gamestats解释select *,其中结果=“是”

请注意上面代码的突出显示部分。我们看到的是使用“ scanfilter”和“ tablescan”。由于Presto仅处理相关信息,因此分析工作流程效率很高。这是下推谓词逻辑的强大功能,也是使S3 Select如此具有影响力的原因。
此示例使用三台DL-380计算机,6个CPU(每个CPU分别具有1 TB和32 GB Ram)来对具有各种数据大小的过滤查询进行MinIO性能测试。X轴表示查询的大小(以GB为单位),Y轴表示时间。为了在整个网络上提供最佳性能,我在节点和NVMe磁盘之间使用了专用的RDMA。网络带宽接近65 GB / s。结果如下:

正如人们所看到的那样,随着数据大小的开始增长,性能改进才真正开始发挥作用,最终仅350 GB就能提供40%到50%的改进。
4.将Weka与Presto JDBC集成
让我们将其带入一个新的水平。现在,我们将使用Java进行一些编码,以将Weka与Presto集成在一起,后者又启用了S3Select,从而使MinIO的连接器就绪。我们将需要对Weka代码进行一些调整,以无缝集成Presto JDBC。下面说明了实现此目的的步骤:
步骤1:确保已安装Java 8 SDK。从这里下载Weka快照。解压缩下载的文件以获取以下文件:

步骤2:进入weka目录。提取weka-src.jar文件,如下所示:

步骤3:将Minstolake目录中的presto-jdbc jar文件复制到提取源中的lib文件夹中。

步骤4:转到步骤2,weka文件夹。打开build.xml。找出名为“ compile”的ant目标(Apache ANT是Weka用来构建发行版jar的构建工具)。添加以下行以将JDBC jar文件分解为类,以便最终的jar也包含我们的JDBC。添加突出显示的部分。如果您知道如何在Java中操作类路径,则可以忽略此设置。

步骤5:创建以下文件的副本

这里需要一些解释。Weka无法理解Universe中所有数据库的所有数据类型。我们需要提供一个映射文件,该文件指定必须如何解释源数据库类型。另外,驱动程序名称和部件在此文件中指定。由于我们的数据类型与Oracle非常相似,因此我们创建了一个副本。高级用户可以创建自己的。
步骤6:编辑以上文件,以添加驱动程序名称和服务器/端口详细信息,如下所示,并将文件另存为DatabaseUtils.props。请同时检查数据类型,如下面的屏幕快照所示。Weka将拥有此文件,但随时可以覆盖:


步骤7:建立一个新的jar文件。转到步骤2,weka文件夹,然后键入“ ant exejar”。假设:您已安装ANT。如果您不租赁,请按照此处的说明进行操作。

如您所见,ANT创建了一个名为dist的新文件夹,并提供了一个名为weka.jar的jar文件。这个罐子是我们将用于下一步的罐子
5.机器学习:基于MinIO数据的Weka决策树
至此,我们已经建立了功能强大的现代化数据湖和分析平台。让我们使用Weka在样本数据上应用主要的分类算法之一,决策树。由于我们已经创建了Presto连接器,因此Weka将连接到Presto,从MinIO中提取数据。在进行下一步之前,请快速检查一下:您必须同时运行MinIO和Presto:

第1步:从您创建分发jar的dist目录中启动Weka:
java -jar weka.jar

点击“资源管理器”
转到窗口下方:

您将看到一个SQL-Viewer窗口。该URL将显示jdbc:presto:// @ servername:8080。将Presto在本地运行,将@servername更改为localhost。您可以点击右侧的第一个按钮以设置用户名和密码。输入任何用户名(在我的情况下为MinIO),并保留密码为空。如果在Presto中启用身份验证并配置https,则需要提供有效的用户ID和密码。

步骤2:单击OK(确定),然后单击右侧的第二个按钮后,您将看到Info(信息)窗格显示状态。现在编写我们的查询。
选择* from minio.games.gamestats //不要在最后加上分号
点击执行按钮。瞧!我们第一个运行中的MinIO浏览器。

现在单击“确定”按钮。您不应获得任何与数据类型相关的错误。如果发现错误,请重新查看我们之前更改的DatabaseUtils.props,然后再次仔细检查。
现在,您将获得功能强大的Weka“预处理”屏幕,您将在其中看到:

步骤3:让我们开始ML动作。通常,当您像上面那样携带数据时,可能会混合使用不同数据类型的列。有些列可能是分类的(您在其中列出了可能的值,通常是字符串)或连续的(离散数字)。您可能需要进行数据清理和转换。为此,Weka通过一系列惊人的过滤器来支持它。您可以通过单击“过滤器”看到它。如果您的数据稀疏,或者您可以删除不相关的值(可能不会为您的ML逻辑添加任何值),甚至我们都可以使用这些选项将某些值替换为null。例如,员工ID在贷款申请结果预测中可能没有任何作用。您在Spark中使用StringIndexer转换数据类型。
对于决策树,单击“分类”按钮。您将在左侧看到一个窗口,其中包含Weka支持的所有算法。选择“树”,然后选择J48。

点击“开始”。让其余选项为默认选项。作为机器学习专家,您知道这些是什么。看到我们创建了一个具有70%准确性的模型。对于像我们这样的少量实验数据,这很好,因为我不想进一步调整它。

将模型保存在您的MinIOlake文件夹中(不保存在MinIO存储中,因为Weka无法读取S3://协议)。将其称为“ MinIOdtree.nodel”。

6.测试我们的决策树模型
现在让我们测试模型。为此,我们将创建一个包含两行的文件,其中不知道我们的预测。将该文件命名为Test.csv。它在下面给出。

观察“?” 分数。我们不知道结果如何,我们希望Weka使用我们创建的模型告诉我们。
步骤1:启动Weka。只需单击“文件按钮”,然后提供任何文件。我们将不会使用此文件。如果您正在读取CSV文件,请更改文件类型。在Weka中,除非您提供一些输入文件,否则无法打开“分类”部分。在“分类”中,进入“结果列表”窗口,右键单击并加载上一节中保存的模型。如下所示:

选择“ MinIOdtree.model”。然后在“测试选项”上单击“提供的测试集”。遍历MinIOlake文件夹并输入“ Test.csv”。

现在单击“更多选项”。确保输出类型为“纯文本”。

完成此操作后,右键单击“结果列表”窗格。单击“在当前测试集上重新评估模型”。

然后你去。您已经使用我们的模型预测了结果:

最后,您可以在Wek中可视化树。右键单击“结果列表”窗格,然后选择“可视化树”以查看如何评估模型。

奖励:从R连接MinIO
你们中有些人可能是R的核心程序员,而Weka的引入可能并没有使他们感兴趣。对于那些R极客,这是个主意:
下载RPresto软件包并安装到您的R环境中。
请确保Presto和MinIO正在运行。再次,没有蜂巢。
以下是代码:
install.packages(“ RPresto”)
install.packages(“ dplyr”)
install.packages(“ dbplyr”)
my_db <-src_presto(catalog =“ MinIO”,schema =“ games”,用户=“ ravi”,host =“本地主机”,端口= 8080,session.timezone =“美国/东部”)
my_tbl <-dplyr.tbl(my_db,“ gamestats”)
my_tbl
4.生成以下输出:

使用变量my_tble,现在您可以在R中编写所有您喜欢的东西。
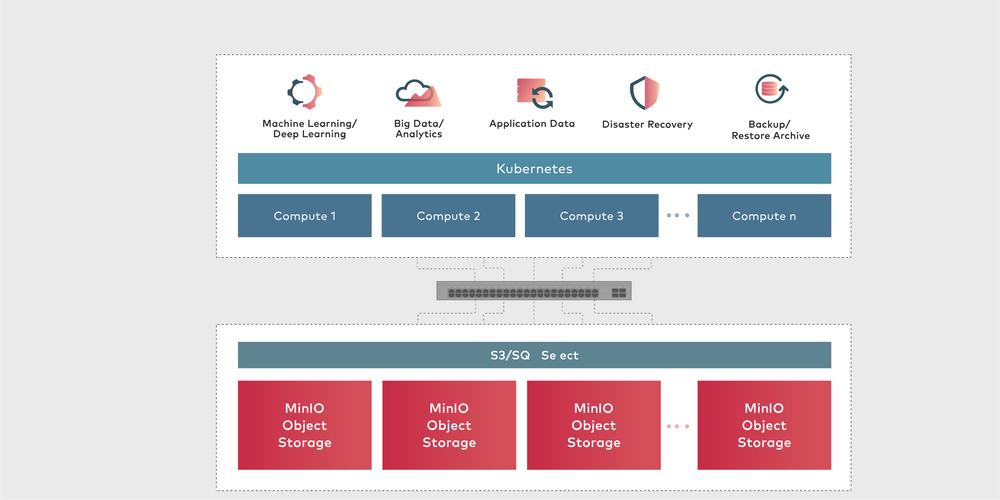
总而言之,让我们来看看我们所做的架构图。

我使用了64 GB的服务器,并且可以对8个属性的约12亿行进行建模。您可以将MinIO群集,将Presto群集以进行更多改进。您可以将NVMe光盘与RDMA连接器一起使用,以提高吞吐量。
希望本文能证明具有MinIO对象存储功能的高级分析框架多么容易和强大。如果您需要更多支持或继续进行对话,请通过LinkedIn与我联系。