使用 Apache Arrow 和 MinIO 构建高性能数据基础设施

这些天围绕 Apache Arrow 的势头很大。作为开发人员和数据从业者的最爱,它在业务关键型应用程序中的使用已大幅增长,Dremio、InfluxData、Snowflake、Streamlit 和 Tellius 等数据驱动组织都投入了大量资金。这种采用的驱动因素是卓越的互操作性、更简单的数据架构、更快的速度和效率、更多的工具选择以及基于 Apache 许可证的供应商锁定的自由。
尽管声势浩大,但阿罗还是有点被误会。虽然Voltron Data的团队现在拥有相当大的资金来改变这种看法并提高知名度,但仍有一些工作要做。我们的好朋友 Ravishankar Nair 几年前做了一篇文章,但我们想添加一点上下文并简化这篇文章中的说明。
Apache Arrow 通过创建任何计算机语言都可以理解的标准柱状内存格式来提高数据分析的速度。Apache Arrow 性能允许在没有序列化成本的情况下传输数据(将数据转换为可以存储的格式的过程)。Apache Arrow 是一个标准,可以由任何处理内存数据的计算机程序实现。
Arrow 已经超越了最初专注于在内存中存储列式数据的范围。它有多个子项目,包括两个查询引擎。同样,让 Voltron Data 团队的商业影响力优先考虑企业功能将加强整个项目。
集成 MinIO 和 Arrow
让我们将注意力转向结合 MinIO 运行 Arrow。
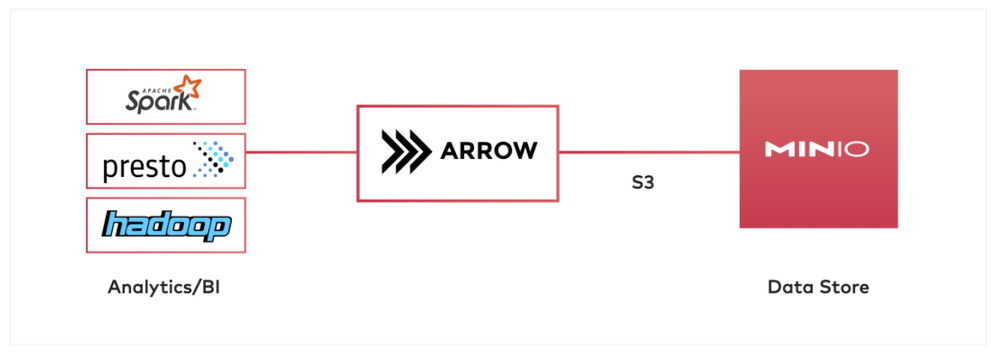
在具有 MinIO 和 Arrow 的架构中,MinIO 将充当数据存储,而 Spark 或 Hadoop 充当数据处理器。Apache Arrow 将在中间使用以将大量数据从 MinIO 转换/加载到 Spark/Hadoop 中。Apache Arrow 可以使用 S3 协议与 MinIO 进行通信。

示例用例:将文件从 CSV 转换为 parquet - 一种用于快速查询的高度优化的柱状数据格式
这是用例的流程:
- Arrow 使用 S3 协议从 MinIO 加载 CSV 文件
- Arrow 在内存中将文件转换为 parquet 格式
- Arrow 将 parquet 格式的数据存储回 MinIO
然后,Spark/Presto 可以直接从 MinIO 中获取 parquet 数据以进行进一步处理。以下是您自己运行此设置的方法:
使用 Docker 运行 MinIO
开始使用 MinIO 的最快方法是使用 Docker。要运行的命令:
这会将 MinIO 设置为独立模式,即 MinIO 的单节点部署。此部署包括一个集成的 Web GUI,称为控制台。运行此命令时,MinIO 的数据 API 将在端口 9000 可用,控制台 UI 将在端口 9001 可用。
创建桶并上传数据
让我们通过在浏览器中访问 127.0.0.1:9001打开 MinIO 控制台。

在 MinIO 控制台中:
导航到左侧菜单栏中的存储桶部分
单击右侧的 [Create Bucket +] 按钮。将新存储桶命名为“testbucket”。
成功创建后,将此文件上传到它 - [username.csv]。
安装 PyArrow
运行此命令以安装 pyarrow:
使用pyarrow从MinIO中读取数据
导入必要的模块
fs:包括 S3Filesystem 实用程序
csv:用于解析CSV文件
parquet:包括将 CSV 转换为 parquet 格式的方法
2. 使用 S3Filesystem 将 pyarrow 连接到 MinIO:
确保传递给 S3Filesystem 的参数与运行 MinIO 的 docker 命令中的命令行参数完全匹配
3.读取CSV文件
4.将其转换为镶木地板
5.验证parquet文件是否创建
导航回 MinIO 控制台
转到左侧菜单栏上的 Buckets
在其中选择'testbucket'和[Browse files]
确保已创建“username.parquet”
就是这样。您已准备好快速阅读和查询。
结论
在本文中,我们介绍了 Apache Arrow 的重要性,以及它与 MinIO 在创建可扩展的高性能数据基础架构方面发挥的作用。示例用例和设置展示了如何使用 Arrow 从 MinIO 加载数据、转换数据并将其存储回 MinIO 以供 Spark、Presto 和任何需要大规模性能的后续处理。