Kubernetes 上的 Dremio 和 MinIO 用于快速可扩展分析
 on
Kubernetes
on
Kubernetes

诸如 MinIO 之类的云原生对象存储经常用于构建数据湖,这些数据湖将大型结构化、半结构化和非结构化数据存储在中央存储库中。数据湖通常包含从多个来源获取的原始数据,包括流和 ETL。组织分析这些数据以发现趋势并衡量业务的健康状况。
什么是 Dremio?
Dremio是一个开源的分布式分析引擎,它为数据探索、转换和协作提供了一个简单的自助服务界面。Dremio 的架构建立在 Apache Arrow 之上,这是一种高性能的柱状内存格式,并利用 Parquet 文件格式进行高效存储。有关 Dremio 的更多信息,请参阅Dremio 入门。
用于云原生数据湖的 MinIO
MinIO 是一个专为云原生应用设计的高性能分布式对象存储系统。可扩展性和高性能的结合使每一个工作负载,无论多么苛刻,都触手可及。最近的一项基准测试在 GET 上达到了 325 GiB/s (349 GB/s),在 PUT 上达到了 165 GiB/s (177 GB/s),只有 32 个现成的 NVMe SSD 节点。
MinIO 旨在为数据湖以及运行在其上的分析和 AI 提供支持。MinIO 包括许多优化,用于处理由许多小文件组成的大型数据集,这在当今的任何开放表格式中都很常见。
也许对于数据湖更重要的是,MinIO 保证了持久性和不变性。此外,MinIO 对传输中和驱动器上的数据进行加密,并使用IAM 和基于策略的访问控制 (PBAC)来规范对数据的访问。
在 Kubernetes 中设置 Dremio OSS
我们可以使用Helm图表在 Kubernetes 集群中部署 Dremio。在这个场景中,我们将使用 Dremio OSS(开源软件)镜像部署一个 Master,三个 Executor 和三个 Zookeeper。Master 节点协调集群和 Executors 处理数据。通过部署多个Executor,我们可以并行处理数据,提高集群性能。
我们将使用 MinIO 存储桶来存储数据。上传到 Dremio 的新文件存储在 MinIO 存储桶中。这使我们能够以可扩展和分布式的方式存储和处理大量数据。
先决条件
要遵循这些说明,您需要
在裸机或kubernetes上运行的 MinIO 服务器,或者您可以使用我们的Play 服务器进行测试。
用于访问 MinIO 服务器的 MinIO 客户端 (mc)。您可以按照本指南在您的机器上安装 mc。
克隆 minio/openlake 回购
MinIO 工程师将 openlake 存储库放在一起,为您提供构建开源数据湖的工具。此存储库的总体目标是指导您完成使用 Apache Spark、Apache Kafka、Trino、Apache Iceberg、Apache Airflow 等开源工具构建数据湖所需的步骤,以及部署在 Kubernetes 上并以 MinIO 作为对象存储的其他工具.
!git clone https://github.com/minio/openlake
创建 MinIO 桶
让我们创建一个 MinIO 桶openlake/dremio,它将被 Dremio 用作分布式存储
克隆 dremio-cloud-tools 回购
我们将使用 Dremio 存储库中的 helm 图表进行设置
我们将使用dremio_v2图表的版本,我们将使用values.minio.yamlopenlake 存储库的 Dremio 目录中的文件来设置 Dremio。我们把YAML复制到dremio-cloud-tools/charts/dremio_v2然后确认已经复制
部署细节
如果我们深入研究该values.minio.yaml文件(随意使用cat或在您选择的编辑器中打开该文件),我们将更深入地了解我们的部署并了解对该部分所做的一些distStorage修改
我们将 设置distStorage为aws,存储桶的名称openlake为 Dremio 的所有存储都将位于前缀dremio(aka s3://openlake/dremio) 下。我们还需要添加,extraProperties因为我们指定了 MinIO 端点。我们还需要添加两个额外的属性以使 Dremio 与 MinIO 一起工作,fs.s3a.path.style.access需要设置为 true 并且dremio.s3.compat必须设置为 true 以便 Dremio 知道这是一个 S3 兼容的对象存储。
除此之外,我们还可以executor根据 Kubernetes 集群容量自定义多个其他配置,例如 CPU 和内存使用情况。我们还可以根据 Dremio 将要处理的工作负载的大小来指定我们需要多少个执行器。
使用 Helm 安装 Dremio
确保更新您的 Minio 端点、访问密钥和密钥values.minio.yaml。下面的命令将安装dremio在新创建的命名空间中命名的 Dremio 版本dremio。
给 Helm 几分钟时间来发挥它的魔力,然后验证 Dremio 是否已安装并正在运行
登录到 Dremio
要登录 Dremio,让我们dremio-client为本地主机的服务打开一个端口转发。执行以下命令后,将浏览器指向http://localhost:9047。为了安全起见,请记得在探索完 Dremio 后关闭端口转发。
首次启动 Dremio 时需要创建一个新用户
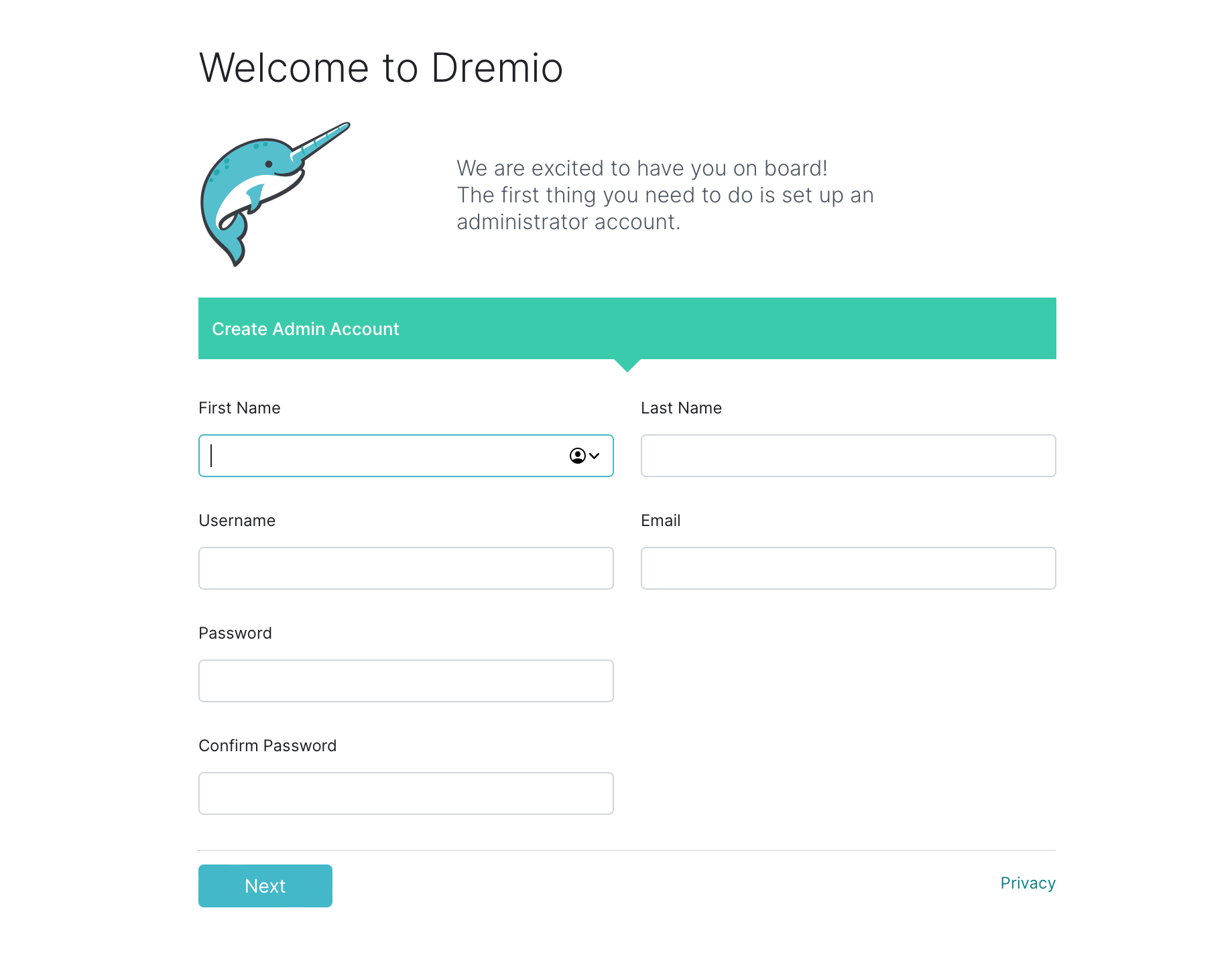
一旦我们创建了用户,我们将看到一个欢迎页面。为了简化此工作流程,让我们将示例数据集上传到包含在 openlake 存储库中的 Dremiodata/nyc_taxi_small.csv并开始查询它。
我们可以openlake/dremio/data/nyc_taxi_small.csv点击首页右上角的+号上传,如下图
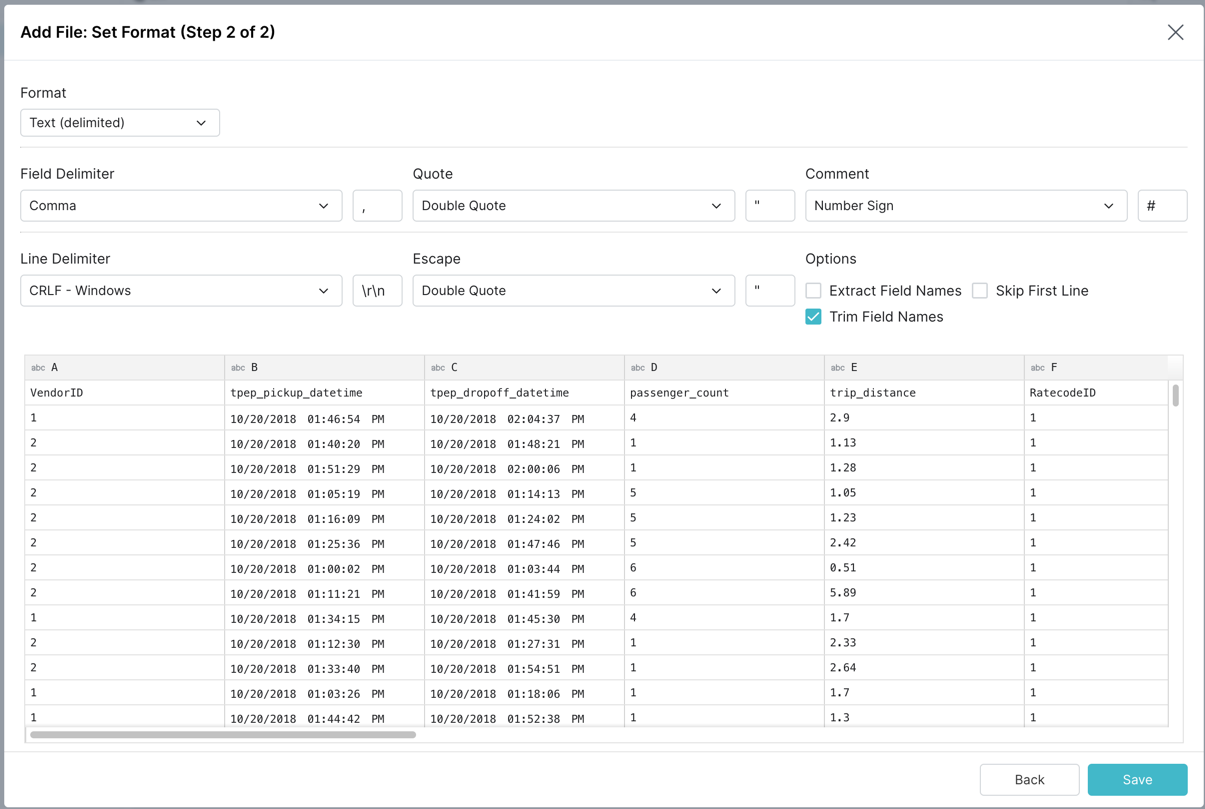
Dremio 将自动解析 CSV 并提供如下所示的推荐格式,单击“保存”继续。
验证 CSV 文件是否已上传到 MinIO 存储桶
加载文件后,我们将被带到 SQL 查询控制台,我们可以在其中开始执行查询。以下是您可以尝试执行的 2 个示例查询
SELECT count(*) FROM nyc_taxi_small; SELECT * FROM nyc_taxi_small;
将上面的内容粘贴到控制台中,然后单击运行,然后您会看到类似下面的内容
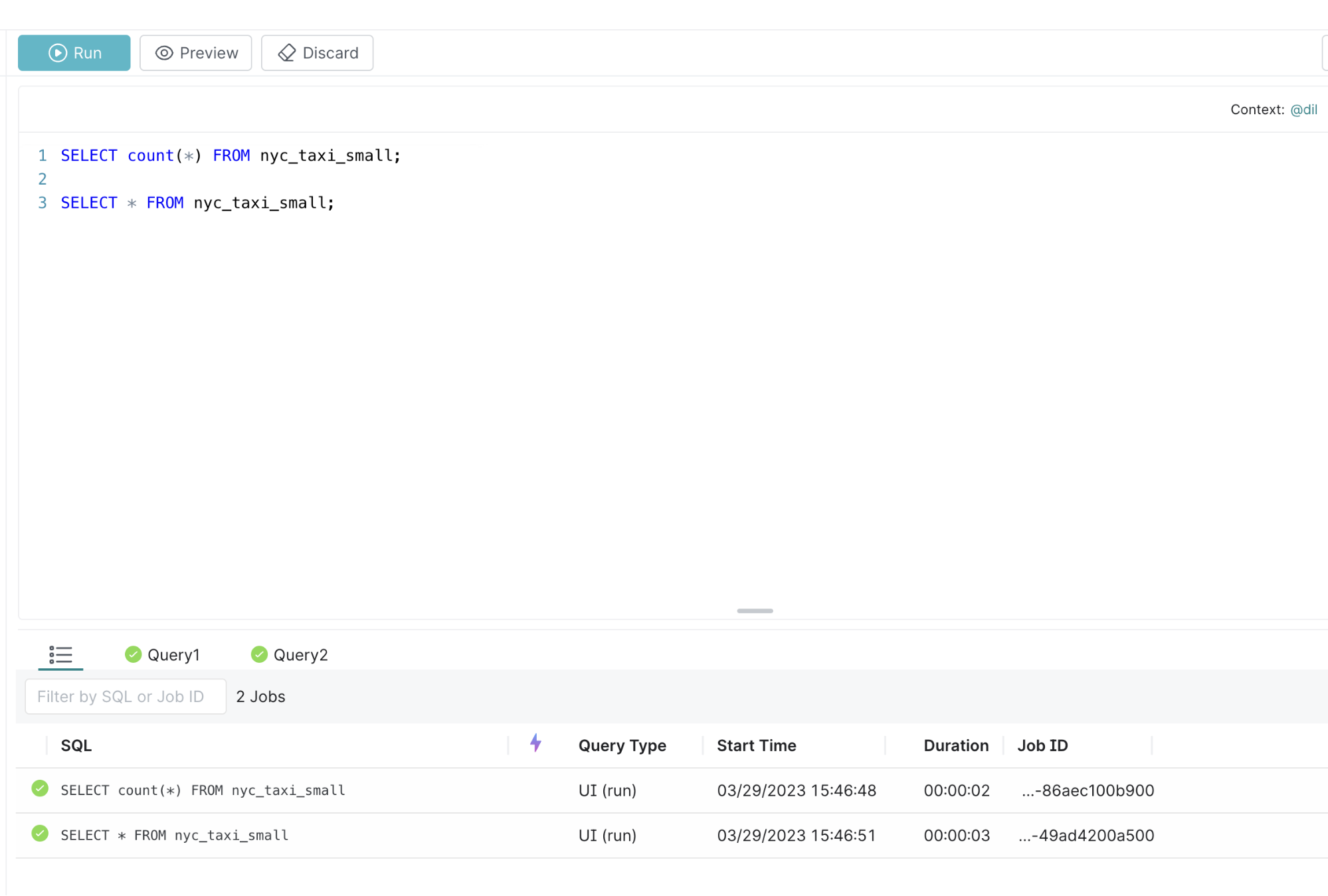
您可以单击选项Query1卡以查看数据集中的行数
您可以单击选项Query2卡以查看数据集中的行数
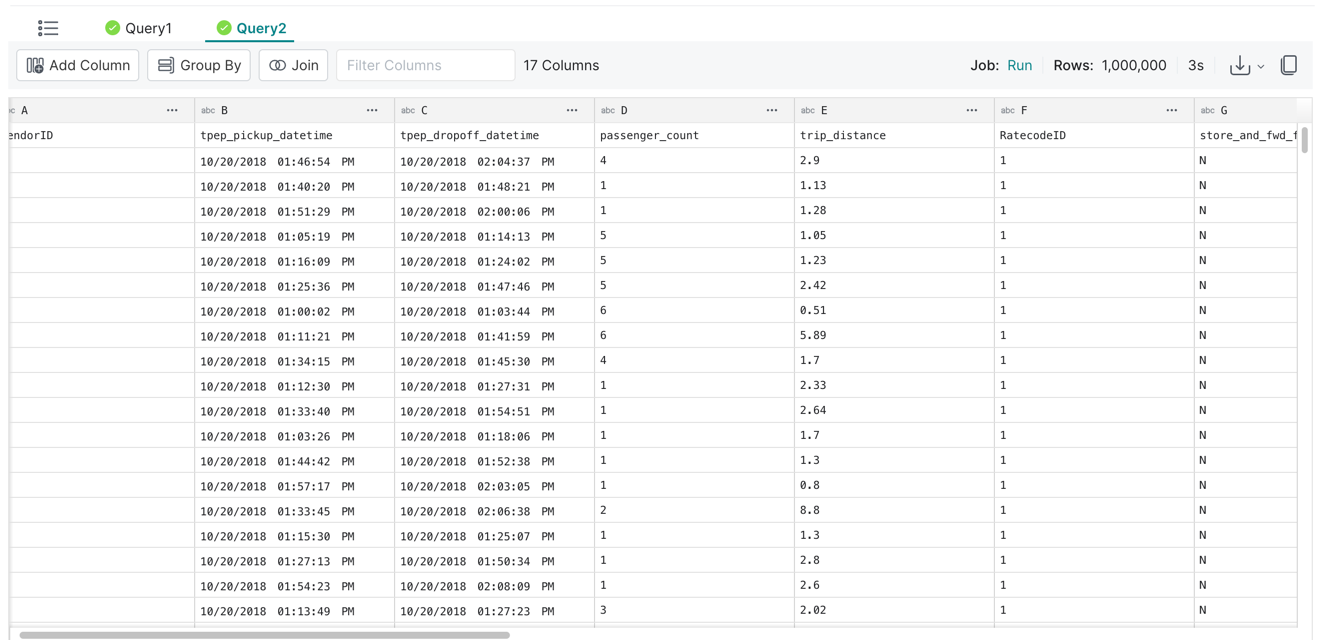
数据湖和 Dremio
这篇博文向您介绍了在 Kubernetes 集群中部署 Dremio 并使用 MinIO 作为分布式存储。我们还看到了如何将示例数据集上传到 Dremio 并开始查询它。在这篇文章中,我们刚刚触及冰山一角,以帮助您开始构建数据湖。
说到冰山,Apache Iceberg 是一种为对象存储而构建的开放表格式。使用 Dremio、 Spark、Iceberg 和 MinIO的组合构建了许多数据湖。要了解更多信息,请参阅The Definitive Guide to Lakehouse Architecture with Iceberg and MinIO。
今天在MinIO上试用 Dremio 。如果您有任何疑问或想分享技巧,请通过我们的Slack 频道联系我们或在 sales@minio.org.cn 上给我们留言。