在MinIO Cloud Storage上使用Presto进行交互式SQL查询

数据分析和查询技术可洞悉用户的需求,行为方式等。随着越来越多的数据进入企业云,分析技术正在不断发展,以帮助企业理解这些数据。
数据分析字段本身并不新鲜;现在已经有相当多的时间使用了各种工具和技术。但是,随着数据量达到历史最高水平,这些工具的效率,响应速度和易用性比以往任何时候都更加重要。
随着企业转向直接与应用程序集成的基于对象存储的私有云,分析技术也必须插入对象存储。这不仅使过程高效,而且易于维护。
在本文中,我们将讨论Presto —一种快速,交互式,开源的分布式SQL查询引擎,用于对大小从GB到PB的数据源运行分析查询。Presto于2012年在Facebook上开发,并于2013年在Apache License V2下开源。Starburst是由该项目的主要贡献者组成的公司,为Presto提供企业支持。他们的工程师最近写了一篇博客文章,内容涉及使用Presto查询对象存储数据湖。
Presto可以使用其连接器连接到各种数据源。我们将特别看一下Hive连接器,它使Presto与Minio服务器对话。通过Presto从您的私有云中的Minio服务器查询数据,您将获得一个安全,高效的数据存储和处理管道。
用例
借助Presto在Minio服务器上运行查询,多个查询用户将使用Minio的相同数据,而产生数据的应用程序将向Minio写入数据。这将导致有效隔离计算层和存储层,从而提供灵活的扩展选项。
然后,可以将此类部署用于各种用例。例如
常规的特殊交互式查询,用于在深入查询之前了解模式。
分析A / B测试结果以了解测试数据中的用户行为。
根据用户数据训练深度学习模型。
为什么选择Minio
Minio是高度可伸缩的高性能对象存储服务器。它可以部署在各种平台上,并且可以直接插入任何使用S3的应用程序中。借助SSE-C,联合身份验证,擦除编码等功能,Minio提供了企业级对象存储解决方案。
这使Minio成为满足私有云存储需求的理想选择。
为什么要Presto
Presto允许查询数据存在的地方,包括Hive,Cassandra,关系数据库甚至专有数据存储。这里有一些优点:
将计算与存储分开,并独立扩展。
单个Presto查询可以合并来自多个来源的数据,从而可以对整个组织进行分析。
凭借其互动性,Presto面向需要响应时间从亚秒到数分钟不等的用例。
Presto由Facebook开发,用于针对多个内部数据存储(包括其300PB数据仓库)进行交互式查询。每天有1000多名Facebook员工使用Presto来运行30,000多个查询,每天总共扫描超过PB。
其他主要的Presto用户包括Netflix(使用Presto来分析存储在AWS S3中的10多个PB数据),AirBnb和Dropbox。
与Hive比较
速度:Presto由于其优化的查询引擎而速度更快,最适合进行交互式分析。蜂巢,相比之下要慢一些。
灵活:Presto的数据源即插即用模型使跨不同数据源的连接和查询变得容易。Hive也可以插入Hadoop存储后端,但是一次只能插入一个。
ANSI SQL:Presto遵循公认的SQL语言ANSI SQL,因此有助于轻松进行查询迁移而没有太多开销。另一方面,Hive具有类似SQL的语法,但并不严格遵守ANSI标准。

要将Presto连接到Minio服务器,我们将使用Presto Hive连接器。为什么选择Hive连接器?Presto使用Hive元数据服务器存储元数据和Hadoops3a文件系统,以从S3对象存储中获取实际数据。这两个都是通过Hive连接器发生的。
Presto仅通过Hive连接器使用元数据和数据。它不使用HiveQL或Hive执行环境的任何部分。
要使用Presto部署Minio,我们需要先设置Hive。只有这样,Presto Hive连接器才能使用hive元数据服务器。
开始Minio服务器 -部署Minio服务器作为解释在这里。然后
presto-minio在您的Minio服务器上创建一个存储桶。稍后我们将使用此存储桶。设置Hadoop -Hadoop是Hive的基础平台。设置Hadoop,如下所示:
在此处从
2.8发布行下载最新的Hadoop版本。将内容解压缩到目录中,我们将其称为Hadoop安装目录。将环境变量
$HADOOP_HOME设置为Hadoop安装目录。还可以PATH使用以下命令更新:export PATH = $ PATH:$ HADOOP_HOME / bin
export SPARK_DIST_CLASSPATH = $(hadoop classpath)打开文件
$HADOOP_HOME/etc/hadoop/hdfs-site.xml并在
<名称> fs.s3a.endpoint
要连接的AWS S3终结点。
fs.s3a.access.key
AWS访问密钥ID。
minio
<属性>
<名称> fs.s3a.secret.key
<描述> AWS密钥。
<值> minio123
<属性>
<名称> fs.s3a .path.style。访问
true
启用S3路径样式访问。
fs.s3a.impl
org.apache.hadoop.fs.s3a.S3AFileSystem
S3A Filesystem的实现
< /属性>
请记住使用上面的Minio服务器端点和访问/秘密键的实际值。
3.设置Hive-通过从此处下载相关的tarball安装Hive的稳定版本。
将内容解压缩到目录中,我们将该目录称为配置单元安装目录。
将环境变量
$HIVE_HOME设置为hive安装目录。使用添加
$HIVE_HOME/bin到您的中PATH,
export PATH=$HIVE_HOME/bin:$PATH
将Hadoop和aws-sdk-java的
jar文件添加到Hive库中:mv〜/ Downloads / hadoop-aws-2.8.2.jar $ HIVE_HOME / lib mv〜/ Downloads / aws-java-sdk-1.11.234.jar $ HIVE_HOME / lib在Hive中创建表之前,请使用下面的HDFS命令创建
/tmp和/user/hive/warehouse(akahive.metastore.warehouse.dir)并设置权限。$ HADOOP_HOME / bin / hadoop fs -mkdir / tmp $ HADOOP_HOME / bin / hadoop fs -mkdir / user / hive /仓库$ HADOOP_HOME / bin / hadoop fs -chmod g + w / tmp $ HADOOP_HOME / bin / hadoop fs -chmod g + w / user / hive /仓库chmod g+w下一步是为Hive $ HIVE_HOME / bin / schematool -dbType derby -initSchema设置架构
我们在derby这里将其用作元数据数据库以进行测试/演示。
使用$ HIVE_HOME / bin / hiveserver2启动Hive服务器
默认情况下,它在端口10000上侦听。
最后,使用$ HIVE_HOME / bin / hiveserver2 --service metastore启动Hive元数据服务器。
默认情况下,元数据服务器侦听端口9083。我们将其用作Presto的元数据服务器。
如果您出于测试目的而执行此操作,并且没有要测试的Hive真实数据,请使用Hive2客户端beeline创建一个表,填充一些数据,然后使用该select语句显示内容。

4. Setup Presto- Presto安装步骤在文档页面上进行了说明。请按照下列步骤并创建相关的配置文件。现在,我们将转到配置Presto Hive连接器以与我们刚刚开始的Hive Metastore对话的步骤。
etc/catalog/hive.properties使用以下内容创建内容以将hive-hadoop2连接器安装为hive目录:connector.name = hive-hadoop2
hive.metastore.uri = thrift://127.0.0.1:9083
hive.metastore-timeout = 1m
hive.s3.aws-access- key = minio
hive.s3.aws-secret-key = minio123
hive.s3.endpoint = http://127.0.0.1:9000
hive.s3.path-style-access = true
hive.s3.ssl.enabled = false
注意,指向上一步中创建的Hive Metastore服务器的Metastore URI。
使用启动Presto服务器
bin/launcher run。您应该在控制台上看到如下消息:

这意味着Presto现在可以启动并运行了。您也可以通过浏览器访问http:// localhost:8080 / ui /上的Presto UI 。

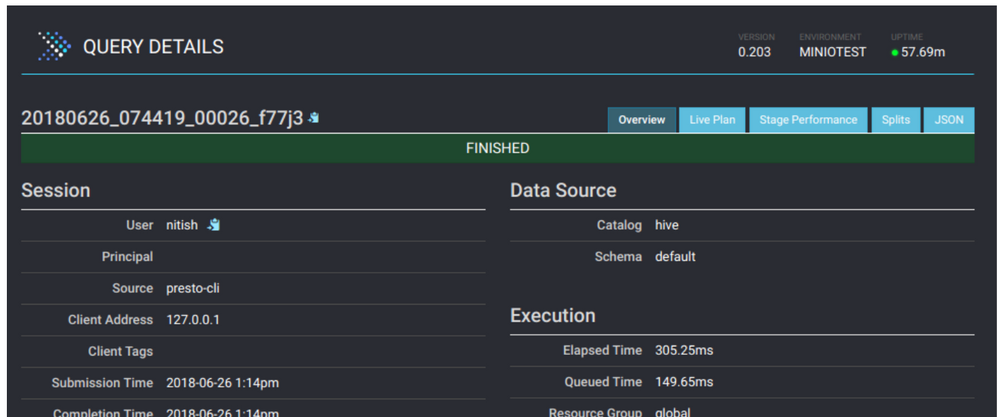
Presto UI还提供了有关正在执行的每个查询的详细信息。单击查询以查看详细信息,例如资源利用率,时间表,工作人员完成的阶段和任务等。这是详细信息页面的外观


现在,您可以使用Presto CLI对存储在Minio服务器上的数据进行查询。您也可以使用Presto客户端之一。
要确认Hive中创建的表是否可以通过Presto客户端使用,请启动cli工具并select为同一表发出一条语句。您应该看到相同的内容。

在这篇文章中,我们了解了为什么从Minio这样的平台查询大型数据集时,Presto为什么以及如何将中心舞台作为首选工具。然后,我们学习了在私有基础架构上设置和部署Presto的步骤。