具有MinIO的Modern Data Lake:第1部分

现在,现代数据湖基于云存储构建,可帮助组织利用对象存储的规模和经济性,同时简化总体数据存储和分析流程。
在这两个系列文章的第一部分中,我们将研究对象存储与其他存储方法的不同之处,以及为什么在数据湖中利用像Minio这样的对象存储是有意义的。
什么是对象存储?
对象存储通常是指平台组织称为对象的存储单元的方式。每个对象通常由三样组成:
数据本身。数据可以是您想要存储的任何内容,从全家福照片到40万页的用于建造火箭的手册。
可扩展数量的元数据。元数据由创建对象存储的任何人定义;它包含有关数据内容,数据用途,机密性或与数据使用方式有关的其他任何内容的上下文信息。
全局唯一标识符。标识符是给对象的地址,因此可以在分布式系统上找到。这样,就可以找到数据而不必知道其物理位置(该数据可能存在于数据中心的不同部分或世界的不同部分)。
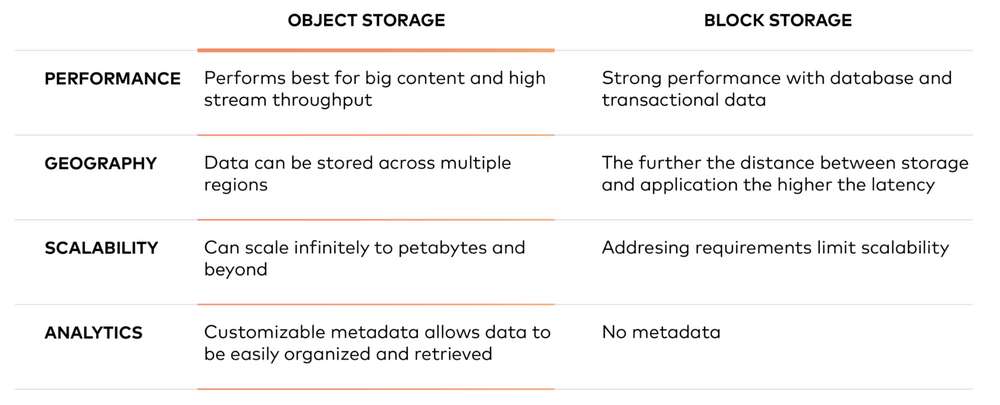
块存储与对象存储

与块存储不同,对象存储不会将文件拆分为原始数据块。而是将数据存储为一个对象,该对象包含由唯一标识符标识的实际文件数据,元数据。请注意,元数据可以包含有关对象的任何文本信息。
现代企业数据中心越来越像私有云,以对象存储作为事实上的存储。对象存储可提供更大的规模经济性,并确保数据以高度可用和高度持久的方式在全球范围内可用。

为什么对象存储很重要?
Hadoop曾经是数据湖的主要选择。但是在当今瞬息万变的技术世界中,城镇已经有了一种现代化的方法。现代数据湖基于对象存储,并且使用 Apache Spark,Presto,Tensorflow等工具进行高级分析和机器学习。
让我们尝试回顾过去,了解情况如何变化。Hadoop诞生于2000年代初期,并在过去五年左右的时间内大受欢迎。实际上,由于许多公司致力于开源,所以五六年前的第一个大数据项目大多数都基于Hadoop。
简而言之,您可以认为Hadoop具有两个主要功能:
分布式文件系统(HDFS)来保留数据。
处理框架(MapReduce),使您可以并行处理所有这些数据。
组织越来越开始希望处理其所有数据,而不仅仅是其中一些数据。因此,Hadoop之所以流行,是因为它具有存储和处理新数据源的能力,包括系统日志,点击流以及传感器和机器生成的数据。
在2008年或2009年左右,这改变了游戏规则。当时,Hadoop对于使您能够使用商品硬件构建本地集群以廉价地存储和处理这些新数据的主要设计目标而言是十全十美的。
当时,这是正确的选择,但今天却不是正确的选择。
火花出现
开源的好处在于它一直在发展。开源的坏处在于它也在不断发展。
我的意思是,随着最新,最大,最好的新项目的推出,您需要玩一些赶超游戏。因此,让我们看一下现在正在发生的事情。
在过去的几年中,出现了一个比MapReduce更新的框架:Apache Spark。从概念上讲,它类似于MapReduce。但是关键的区别在于,它经过了优化,可以处理内存而不是磁盘中的数据。当然,这意味着在Spark上运行的算法会更快,而且通常会更快。
实际上,如果您今天开始一个新的大数据项目,并且对与旧版Hadoop或MapReduce应用程序互操作没有强制性要求,那么您应该使用Spark。您仍然需要保留数据,并且由于Spark已与许多Hadoop发行版捆绑在一起,因此大多数本地群集都使用了HDFS。可以,但是随着云的兴起,存在一种更好的持久化数据的方法:对象存储。
对象存储与文件存储和块存储的不同之处在于,对象存储将数据保存在一个“对象”中,而不是将一个块组成一个文件。元数据与该文件相关联,从而消除了文件存储中使用的分层结构的需要-对可以使用的元数据数量没有限制。一切都放在一个可轻松扩展的平面地址空间中。
对象存储具有多个优点
本质上,对象存储对于大内容和高流吞吐性能非常好。它允许将数据存储在多个区域中,可以无限扩展至PB甚至更高,还提供可自定义的元数据以帮助检索文件。
许多公司,特别是那些运行私有云环境的公司,将对象存储库视为大量海量非结构化数据的长期存储库,出于合规性原因,这些数据需要保留。
但这不仅仅是出于合规性原因的数据。公司使用对象存储将照片存储在Facebook上,将歌曲存储在Spotify上,并将文件存储在Dropbox中。
成本可能会导致大多数人的视线不佳。对象存储的大容量存储成本远远低于HDFS所需的块存储。根据货比三家,您会发现对象存储的成本大约是块存储的1/3至1/5(请记住,HDFS需要块存储)。这意味着在HDFS中存储相同数量的数据可能是将其存储在对象存储中的成本的三到五倍。
因此,Spark是一个比MapReduce更快的框架,并且对象存储比具有块存储要求的HDFS便宜。但是,让我们停止孤立地看待这两个组件,并整体看待新架构。
结合对象存储和Spark的好处
我们特别推荐的是基于对象存储和Spark在云中构建数据湖。这种组合比基于Hadoop的数据湖更快,更灵活且成本更低。让我们进一步解释。
与典型的Hadoop / MapReduce配置相比,将云中的对象存储与Spark结合起来更具弹性。如果您曾经尝试过向Hadoop集群添加和减少节点,那么您就会明白我的意思。可以做到,但这并不容易,而同一任务在云中却微不足道。
但是还有另一个方面的弹性。使用Hadoop,如果要添加更多存储,可以通过添加更多节点(带有计算)来实现。如果需要更多的存储,无论是否需要,您都将获得更多的计算量。
对于对象存储体系结构,情况有所不同。如果您需要更多计算,则可以启动新的Spark群集,而不必理会您的存储。如果您刚刚获取了数TB的新数据,则只需扩展对象存储即可。在云中,计算和存储不仅具有弹性。它们具有独立的弹性。那样很好,因为您对计算和存储的需求也具有独立的弹性。
您可以从对象存储和Spark获得什么?
业务敏捷性:所有这些都意味着您的绩效可以提高。您可以根据需要启动许多不同的计算集群。具有大量RAM,重型通用计算或用于机器学习的GPU的集群-您可以根据需要并同时进行所有这些操作。
通过根据您的计算需求定制集群,您可以更快地获得结果。当您不使用群集时,可以将其关闭,这样您就不必为它付费。
使用对象存储成为数据湖中数据的持久性存储库。在云上,您只需支付存储的数据量,就可以随时添加或删除数据。
这种新发现的灵活性在分配和使用资源方面的实际效果是为企业带来了更大的灵活性。当出现新要求时,您可以启动独立的群集来满足该需求。如果另一个部门想要利用您的数据,那也是可能的,因为所有这些集群都是独立的。
稳定性和可靠性:长时间运行稳定可靠的Hadoop集群所提供的不仅仅是复杂性。
如果您有本地解决方案,则升级群集通常意味着先关闭整个群集并升级所有组件,然后再重新启动它。但是这样做意味着在发生这种情况时您无法访问该群集,如果遇到困难,这可能会很长时间。当您再次将其备份时,可能会发现新问题。
滚动升级(逐节点)是可能的,但是这仍然是一个非常困难的过程。因此,不被广泛推荐。不仅是升级和修补程序,运行和调整Hadoop集群还可能涉及调整多达500个不同的参数。
解决此类问题的一种方法是通过自动化。
但是云为您提供了另一种选择。完全托管的Spark和对象存储服务可以为您完成所有工作。备份,复制,修补,升级,调整全部外包。
在云中,将稳定性和可靠性的责任从您的IT部门转移到了云供应商,无论是私有云还是公共云。
降低了总拥有成本:将管理对象存储/ Spark配置的工作转移到云上也有另一个优势。您实际上是将工作的存储管理部分外包给了供应商。这是一种让您的员工参与并从事激动人心的项目,同时节省成本并降低总拥有成本的方法。
尽管这很重要,但这种新架构的较低的总拥有成本不仅仅在于降低人工成本。请记住,对象存储比HDFS所需的块存储便宜。独立的弹性缩放确实意味着要为您使用的东西付费。
在本质上
我们将基于对象存储和Spark的新数据湖架构的优势归结为三个:
提高业务敏捷性
更高的稳定性和可靠性
降低总拥有成本
在本系列的下一篇也是最后一篇文章中,我们将大致了解对象存储体系结构,然后了解如何将Minio对象存储与Apache Spark和Presto之类的工具集成,以简化整个组织的数据流。