Kubeflow Pipelines (KFP) 是 Kubeflow 最受欢迎的功能。 Python 工程师可以使用 KFP 装饰器将用普通旧 Python 编写的函数转换为
在 Kubernetes 中运行的 组件。 如果您使用 KFP v1,请注意 - KFP v2 中的编程模型非常不同 - 然而,这是一个很大的改进。 将普通
的旧 Python 转换为可重用组件并将这些组件编排到管道中要容易得多。
在这篇文章中,我想超越强制性的“Hello World”演示,并展示一些东西,我希望您能找到直接可用的东西,或者至少找到一个用于插入您自己的逻辑的框架。
我要做的是展示如何构建一个 KFP Pipeline,用于下载美国人口普查局数据(这是一个可免费访问的公共数据集)并将该数据保存到 MinIO。 MinIO 是存储
ML 数据和模型的好方法。 使用 MinIO,您可以保存训练集、验证集、测试集和模型,而无需担心规模或性能。 此外,有一天人工智能将会受到监管;
当这一天到来时,您将需要 MinIO 的企业功能(对象锁定、版本控制、加密和合法锁定)来保护您的静态数据,并确保您不会意外删除监管机构可能要求的内容。
您可以在此处详细了解我们将使用的数据。 要获取人口普查 API 的 API 密钥,请访问人口普查局的开发人员网站。 这很简单。 您所需要做的就是指定一个电子
邮件地址。
我们将构建什么 在这篇文章中,我将构建一个管道,该管道采用表代码(人口普查局数据集中的标识符 )和年份作为参数。如果我们之前没有下载过该表,它将通过 API
下载该表。
如果我们之前没有下载过表格,我们只会调用人口普查 API。当我们调用 ACS API 时,我们会将数据保存在我们设置用于存储原始数据的 MinIO 实例中。
这与 KFP 内部使用的 MinIO 实例不同。我们本可以尝试使用 KFP 的 MinIO 实例 - 然而,这不是 ML 数据管道的最佳设计。
由于我之前描述的原因,您将需要一个完全由您控制的存储解决方案。下面是我们的 Kubeflow 和 MinIO 部署的图表,说明了每个 MinIO 实例的用途。
在开始编写代码之前,让我们创建管道的逻辑设计。
逻辑管道设计
您在 KFP 中运行的管道称为有向无环图 (DAG)。它们朝一个方向移动并且不会原路返回——没有闭环。这就是您对数据管道的期望。
下面是我们将在 KFP 中构建和运行的 DAG 的逻辑设计。这是不言自明的。从概念工作流程开始是帮助您将逻辑转换为能够充分利用 KFP 的功能的好方法。
现在我们有了逻辑设计,让我们开始编码。 我假设您已经安装了 KFP 并且还设置了自己的 MinIO 实例。 如果您没有安装 KFP 2.0 和 MinIO,
请查看 使用 Kubeflow Pipeline 2.0 和 MinIO 设置开发机器 。
从逻辑设计创建 Python 函数 上面逻辑设计中的每个任务都将成为一个Python函数。 下面的函数签名显示了如果我们编写 Python 脚本或没有 KFP 的独立服务,参数和返回值将如何设计。
如果您要将现有代码迁移到 KFP,我想讨论一下这个问题。
def survey_data_exists (survey_code: str, year: int) -> bool: '''Check MinIO to see if the survey data exists.''' pass def download_survey_data (table_code: str, year: int) -> pd.DataFrame: '''Download the survey data using the CB API and return a Pandas dataframe.''' pass def save_survey_data (bucket: str, object_name: str, survey_df: pd.DataFrame) -> None : '''Save the survey data which is a Pandas dataframe to the MinIO bucket.''' pass def get_survey_data (bucket: str, object_name: str) -> pd.DataFrame: pass
关于上述功能的一些评论。 他们使用类型提示。 如果您正在编写普通的旧式 Python,则可以选择不使用类型提示,因为它们是可选的。 在 Kubeflow Pipelines 中,它们不是 - 您必须使用类型提示,以便 KFP 可以告诉您在将函数组装到管道中时参数和返回值是否不匹配。 这是一件好事。 当您编译管道时,KFP 会发现类型不匹配错误。 在集群内运行时很难追踪这些相同的错误。
组合功能可能很诱人,这样您就可以管理更少的功能。 例如,可以使用简单的“if else”语句将最后三个函数合并为一个,然后就不需要第一个函数了。 使用 KFP 等工具时,这不是最佳实践。 正如我们将看到的,KFP 具有条件和循环的构造。 通过使用 KFP 构造,您将在 KFP UI 中获得更好的管道可视化效果。 并行也是可能的,这将提高管道性能。 最后,如果我们保持函数简单,我们将获得更好的重用。
我们现在准备使用 Python 函数创建 Kubeflow Pipeline 组件。
从 Python 函数创建 KFP 组件 下面的代码是我们的 Pipeline 组件的完整实现。 当您使用 KFP 和 MinIO 等工具时,您实际上不需要编写大量管道代码。
@dsl.component(packages_to_install=['minio==7.1.14']) def table_data_exists (bucket: str, table_code: str, year: int) -> bool: ''' Check for the existence of Census table data in MinIO. ''' from minio import Minio from minio.error import S3Error import logging object_name= f' {table_code} - {year} .csv' logger = logging.getLogger( 'kfp_logger' ) logger.setLevel(logging.INFO) logger.info(bucket) logger.info(table_code) logger.info(year) logger.info(object_name) try : # Create client with access and secret key. client = Minio( 'host.docker.internal:9000' , 'Access key here.' , 'Secret key here.' , secure= False ) bucket_found = client.bucket_exists(bucket) if not bucket_found: return False objects = client.list_objects(bucket) found = False for obj in objects: logger.info(obj.object_name) if object_name == obj.object_name: found = True except S3Error as s3_err: logger.error( f'S3 Error occurred: {s3_err} .' ) except Error as err: logger.error( f'Error occurred: {err} .' ) return found @dsl.component(packages_to_install=['pandas==1.3.5', 'requests']) def download_table_data (dataset: str, table_code: str, year: int, table_df: Output[Dataset]): ''' Returns all fields for the specified table. The output is a DataFrame saved to csv. ''' import logging import pandas as pd import requests logger = logging.getLogger( 'kfp_logger' ) logger.setLevel(logging.INFO) census_endpoint = f'https://api.census.gov/data/ {year} / {dataset} ' census_key = 'Census key here.' # Setup a simple dictionary for the requests parameters. get_token = f'group( {table_code} )' params = { 'key' : census_key, 'get' : get_token, 'for' : 'county:*' } # sending get request and saving the response as response object response = requests.get(url=census_endpoint, params=params) # Extract the data in json format. # The first row of our matrix contains the column names. The remaining rows # are the data. survey_data = response.json() df = pd.DataFrame(survey_data[ 1 :], columns = survey_data[ 0 ]) df.to_csv(table_df.path, index= False ) logger.info( f'Table {table_code} for {year} has been downloaded.' ) @dsl.component(packages_to_install=['pandas==1.3.5', 'minio==7.1.14']) def save_table_data (bucket: str, table_code: str, year: int, table_df: Input[Dataset]): import io import logging from minio import Minio from minio.error import S3Error import pandas as pd object_name= f' {table_code} - {year} .csv' logger = logging.getLogger( 'kfp_logger' ) logger.setLevel(logging.INFO) logger.info(bucket) logger.info(table_code) logger.info(year) logger.info(object_name) df = pd.read_csv(table_df.path) try : # Create client with access and secret key client = Minio( 'host.docker.internal:9000' , 'Access key here.' , 'Secret key here.' , secure= False ) # Make the bucket if it does not exist. found = client.bucket_exists(bucket) if not found: logger.info( f'Creating bucket: {bucket} .' ) client.make_bucket(bucket) # Upload the dataframe as an object. encoded_df = df.to_csv(index= False ).encode( 'utf-8' ) client.put_object(bucket, object_name, data=io.BytesIO(encoded_df), length=len(encoded_df), content_type= 'application/csv' ) logger.info( f' {object_name} successfully uploaded to bucket {bucket} .' ) logger.info( f'Object length: {len(df)} .' ) except S3Error as s3_err: logger.error( f'S3 Error occurred: {s3_err} .' ) except Error as err: logger.error( f'Error occurred: {err} .' ) @dsl.component(packages_to_install=['pandas==1.3.5', 'minio==7.1.14']) def get_table_data (bucket: str, table_code: str, year: int, table_df: Output[Dataset]): import io import logging from minio import Minio from minio.error import S3Error import pandas as pd object_name= f' {table_code} - {year} .csv' logger = logging.getLogger( 'kfp_logger' ) logger.setLevel(logging.INFO) logger.info(bucket) logger.info(table_code) logger.info(year) logger.info(object_name) # Get data of an object. try : # Create client with access and secret key client = Minio( 'host.docker.internal:9000' , 'Access key here.' , 'Secret key here.' , secure= False ) response = client.get_object(bucket, object_name) df = pd.read_csv(io.BytesIO(response.data)) df.to_csv(table_df.path, index= False ) logger.info( f'Object: {object_name} has been retrieved from bucket: {bucket} in MinIO object storage.' ) logger.info( f'Object length: {len(df)} .' ) except S3Error as s3_err: logger.error( f'S3 Error occurred: {s3_err} .' ) except Error as err: logger.error( f'Error occurred: {err} .' ) finally : response.close() response.release_conn()
在实现这些函数并对其进行故障排除时要记住的最重要的事实是,在运行时它们根本不是函数。 它们将是组件。 换句话说,KFP 会将每个功能部署到自己的容器中。 此示例使用轻量级 Python 组件。 您还可以使用容器化的 Python 组件,这使您可以更好地控制放入容器中的内容。 还有一个适用于非 Python 代码的容器化组件选项。
KFP 引入了多种构造来帮助您无缝创建可以充当容器中运行的独立组件的函数。 它们是组件装饰器、参数和工件。 让我们逐步了解这些工具,以便您了解 KFP 如何在运行时部署函数并在它们之间传递数据。
成分 组件装饰器告诉 KFP 函数应该作为组件部署。 仔细看一下上面代码中这个装饰器是如何使用的。 由于该函数将单独部署到容器中,因此您需要告诉 KFP 其依赖项。 这是使用装饰器的packages_to_install 参数完成的。 这仅确保安装依赖项(通过 pip)。 它不会为您导入它们。 您需要在函数定义中自己执行此操作。 这可能看起来有点不正统,因为我们大多数人都习惯在模块级别导入依赖项 - 但当使用像 KFP 这样将功能转变为服务的工具时就可以了。
在组件之间传递数据必须小心。 KFP v2 对参数和工件进行了区分。 参数用于在函数调用之间传递的简单数据(int、bool、str、float、list、dict)。 另一方面,工件表示您的函数从外部源检索或创建的数据 - 例如描述模型准确性的数据集、模型和指标。 如果您想要设计输出的样式,使其在 Kubeflow UI 中更美观,您甚至可以使用工件来创建 HTML 和 Markdown。 由于工件可能很大,KFP 使用自己的 MinIO 实例来存储它们。
参数(和返回值) KFP 使用 Python 类型提示来指定简单的输入参数和简单的返回值。 您只能使用 str、int、float、bool、list 和 dict。 上面的 table_data_exists 函数显示了如何在函数签名中指定参数。 从语法上讲,您可以像使用标准 Python 一样指定它们。 请记住使用类型提示是一个要求。 在运行时,KFP 负责在不同容器中运行的组件之间整理这些值。
如果函数需要更复杂的数据类型作为输入或者返回复杂的数据类型,则使用工件。
Artifacts 工件与输入参数和输出值不同,因为它们可能会变大。 工件的示例包括:数据集、模型、指标(ML 训练工作的结果)、HTML 和 Mark Down。 在底层,KFP 使用自己的 MinIO 实例来存储工件。 当您将工件从一个组件传递到另一个组件时,KFP 不会直接传递工件 - 而是将工件存储在 MinIO 中,并在 MinIO 中传递对工件(对象)的引用。 这实在是太聪明了。 这意味着,如果您有一个需要由多个组件访问的大型工件,那么这些组件可以有效地访问该工件 - 因为 MinIO 是专门为高效的对象存储和访问而构建的。
让我们看看当您将工件传递给组件时会发生什么。 在上面的代码示例中,save_table_data 显示了这是如何完成的。 在调用您的函数之前,KFP 将工件从其 MinIO 实例复制到您的组件正在运行的容器的本地文件系统。您的代码将需要读取此文件。 这是使用您声明为 Input[Dataset] 类型的参数的路径属性来完成的。 在 save_table_data 函数中,我将此文件读入 Pandas DataFrame。
输出工件被指定为函数参数,并且不能是函数的返回值。 在上面的代码中,get_table_data 显示了如何使用输出工件。 请注意,table_df 参数的数据类型为 Output[Dataset]。 要成功从函数返回数据,必须将数据写入参数路径属性中指定的位置。 同样,这是对容器中本地文件系统的引用 - 当您的函数完成时,KFP 将负责将此文件移至其 MinIO 实例。
我们现在准备将组件组装到管道中。
从组件创建管道 下面的代码根据我们在上一节中实现的组件创建我们的管道(或 DAG)。
@dsl.pipeline( name= 'census-pipeline' , description= 'Pipeline that will download Census data and save to MinIO.' ) def census_pipeline (bucket: str, dataset: str, table_code: str, year: int) -> Dataset: # Positional arguments are not allowed. # When I set the name parameter of the condition that task in the DAG fails. exists = table_data_exists(bucket=bucket, table_code=table_code, year=year) with dsl.Condition(exists.output == False ): table_data = download_table_data(dataset=dataset, table_code=table_code, year=year) save_table_data(bucket=bucket, table_code=table_code, year=year, table_df=table_data.outputs[ 'table_df' ]) with dsl.Condition(exists.output == True ): table_data = get_table_data(bucket=bucket, table_code=table_code, year=year) return table_data.outputs[ 'table_df' ]
这个函数中有一些值得注意的事情。 首先,管道装饰器告诉 KFP 该函数包含我们的管道定义。 您在此处指定的名称和描述将显示在 KFP UI 中。
接下来,这个管道函数的返回值是一个Dataset。 事实证明,管道可以像组件一样使用。 当管道有返回值时,它可以在另一个管道中使用。 这是重用组件的好方法。
最后,我们使用 dsl.Condition(这是一个 Python 上下文管理器)仅在我们需要的数据不在 MinIO 实例中时才调用我们的下载组件。 我们可以在这里使用传统的 if 语句。 然而,如果我们这样做,那么 KFP 将无法知道我们的逻辑中有一个分支。 通过使用 dsl.Condition 构造,我们向 KFP 告知管道中的一个分支。 这将使 KFP UI 为我们提供更好的视觉呈现。
运行管道 一旦您实现了组件和管道,您只需两行代码即可运行管道。
client = Client() run = client.create_run_from_pipeline_func(census_pipeline, experiment_name= 'Implementing functions' , enable_caching= False , arguments={ 'bucket' : 'census-data' , 'table_code' : 'B01001' , 'year' : 2020 } )
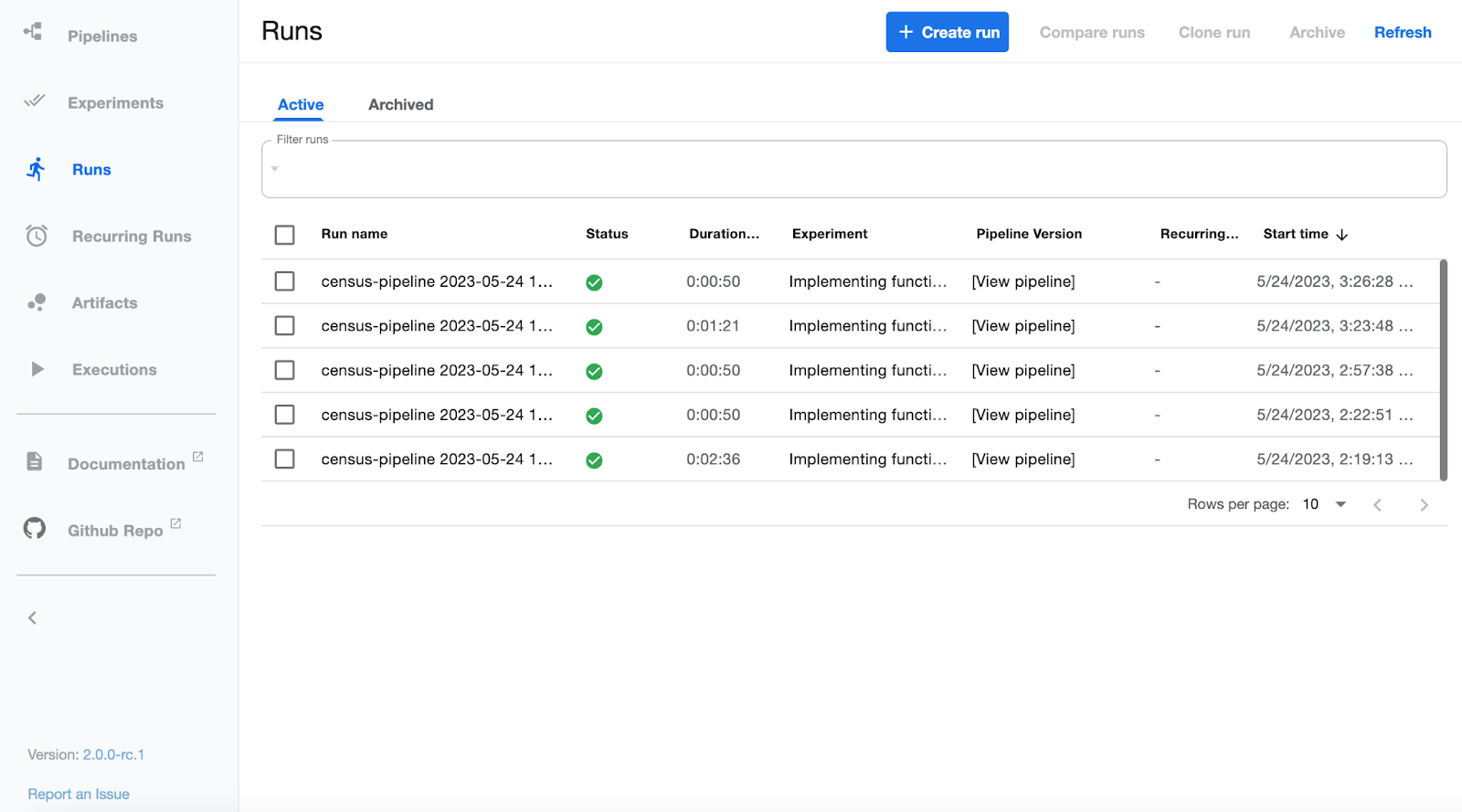
选择一个有意义的实验名称。 KFP UI 有一个实验选项卡,可以对具有相同实验名称的运行进行分组。 上面的代码“编译”您的管道和组件 - 这仅仅是将所有内容放入 YAML 文件(包括源代码)的行为。 如果您有我之前描述的任何类型不匹配,那么您将在创建运行时发现这些问题。 此代码还将您的管道发送到 KFP 并运行它。 下面的屏幕截图显示了我们管道的一些成功运行。
概括 在这篇文章中,我们创建了一个数据管道,它使用 KFP 和 MinIO 下载并保存美国人口普查数据。 为此,我们设置了自己的 MinIO 实例来存储原始数据。 这是 ML 管道的重要组成部分 - 有一天,人工智能将受到监管,并且拥有受您控制的存储解决方案可以让您对用于训练的数据和模型本身进行版本控制、锁定和加密。
我们还讨论了 KFP 如何使用自己的 MinIO 实例在管道运行期间有效地保存和访问工件。
在我的下一篇文章中,我将展示如何将此数据管道用作另一个使用人口普查数据训练模型的管道的输入。
 on
Kubernetes
on
Kubernetes