Erasure Coding(纠删码)对 MinIO 中 CPU 利用率的影响和性能评估


纠删码是 MinIO 的核心功能。它是为分布式设置提供高可用性的基石之一。简而言之,写入MinIO的对象被分割成多个数据分片(M)。为了补充这些,我们创建了许多奇偶校验分片 (K)。然后这些分片分布在多个磁盘上。只要有 M 个可用分片,就可以重建对象数据。这意味着我们可以失去对 K 个分片的访问而不会丢失数据。
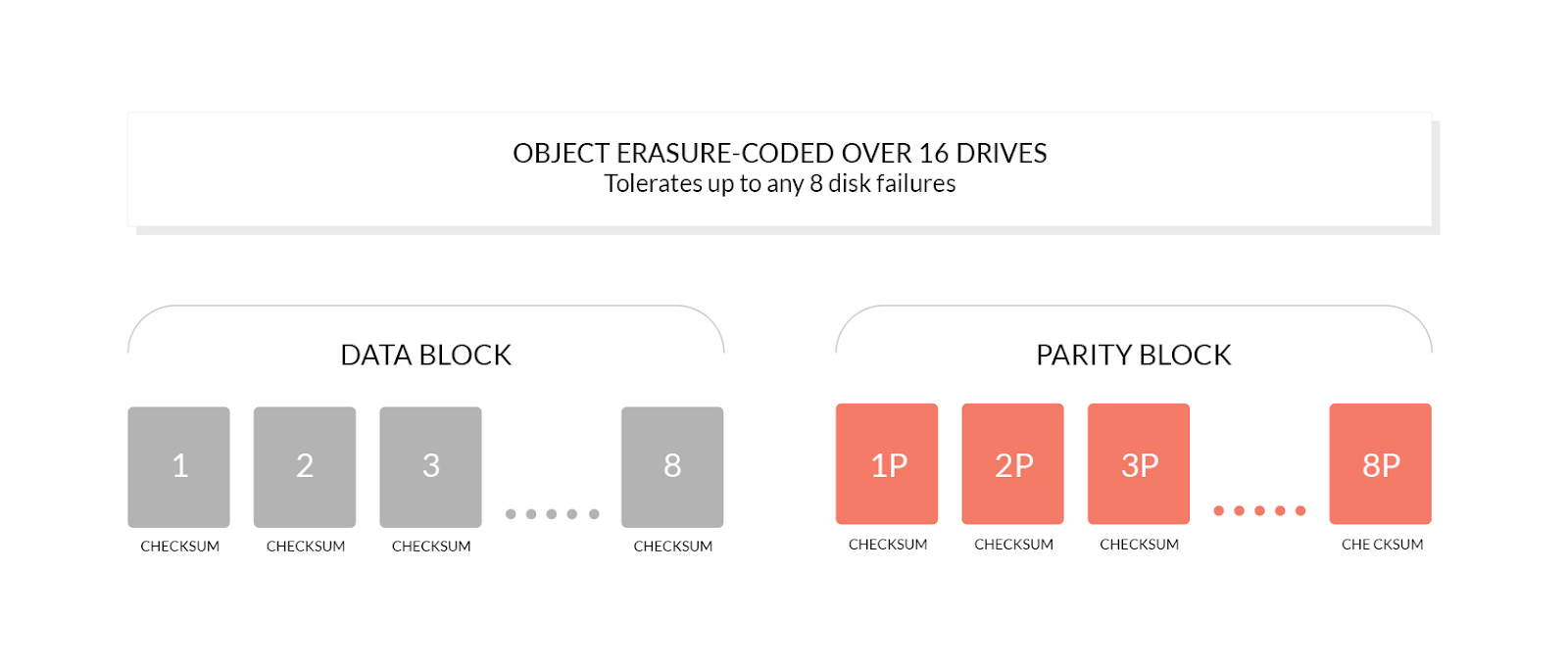
测试设置
为了测试各种平台的性能,我们创建了一个小型应用程序和一个随附的脚本,用于在 MinIO 的实际场景中对性能进行基准测试。
块大小:1MiB
块:1024
中号/中号:12/4、8/8、4/4
线程:1->128
所有 MinIO 对象都以最大 1MiB 的块形式写入,该块除以我们要写入数据分片的驱动器数量。因此,我们在测试中保持这个数字不变。
该基准测试在 1024 个块上运行。这意味着输入是 1GiB 的数据。这是为了从等式中消除 CPU 缓存。我们这样做是为了测试最坏情况下的性能,而不仅仅是数据位于 L1/L2/L3 缓存中时的性能。
选择 CPU 是为了全面了解不同平台的性能。
英特尔® 至强® 铂金 8461V(Sapphire Rapids,48 核,96 线程)
2 个英特尔® 至强® Gold 6338(Ice Lake,2 个 32 核,128 线程)
AMD EPYC 7R13(Milan,48 核,96 线程)
Amazon Graviton 3(ARM,64 核,64 线程)
请参阅文章末尾的测量数据链接。
基准测试
我们测量了三种不同纠删码配置的编码和解码速度。
编码12+4
首先,我们通过将对象分片到 16 个磁盘的设置来考察编码速度。使用默认设置,MinIO 会将数据拆分为 12 个分片并创建 4 个奇偶校验分片。我们将使用不同数量的核心进行计算来查看速度。这是上传对象到MinIO时执行的操作。为了使其能够轻松地与 NIC 速度进行比较,我们以每秒千兆位为单位显示速度。
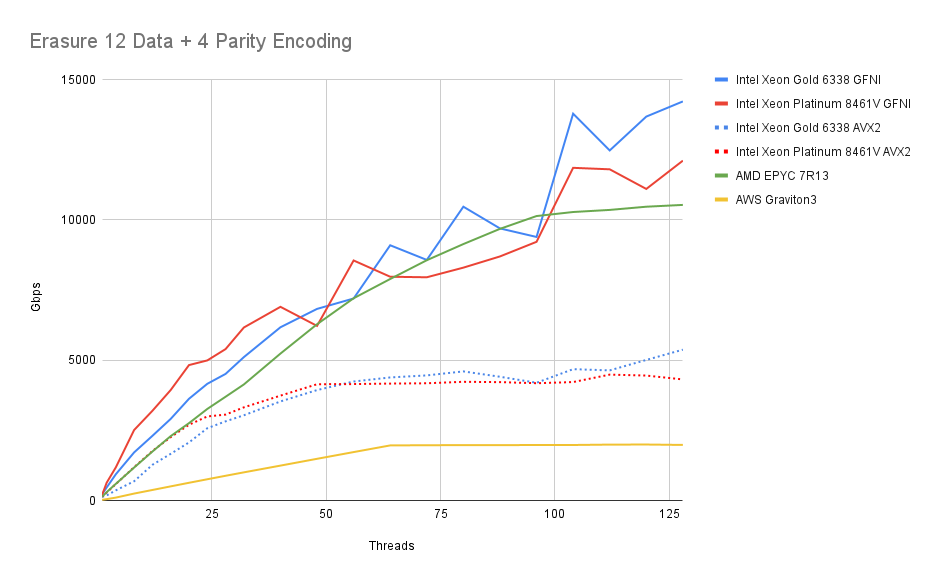
在此图表中,我们可以看到我们的性能很快就超过了顶级 400Gibps NIC - 事实上,所有 x86-64 平台都可以使用少于 4 个线程来完成此操作,其中 Graviton 3 需要大约 16 个内核。
较旧的双插槽 Intel CPU 几乎可以跟上新一代单插槽 Intel CPU。尽管 GFNI 在这一代 CPU 上不可用,但 AMD 仍与 Intel 保持着良好的关系。出于好奇,我们还测试了没有 GFNI 的 Intel CPU,仅使用 AVX2。
正如我们所期望的,当我们达到其核心数量时,我们会看到 Graviton 3 达到最大。
解码12+4
接下来我们看看重建对象时的性能。即使在本地分片包含奇偶校验以减少远程调用数量的情况下并不严格需要,MinIO 也会重建对象。
设置与上面类似。对于每个操作,从剩余数据重建 1 到 K(此处为 4)个分片。
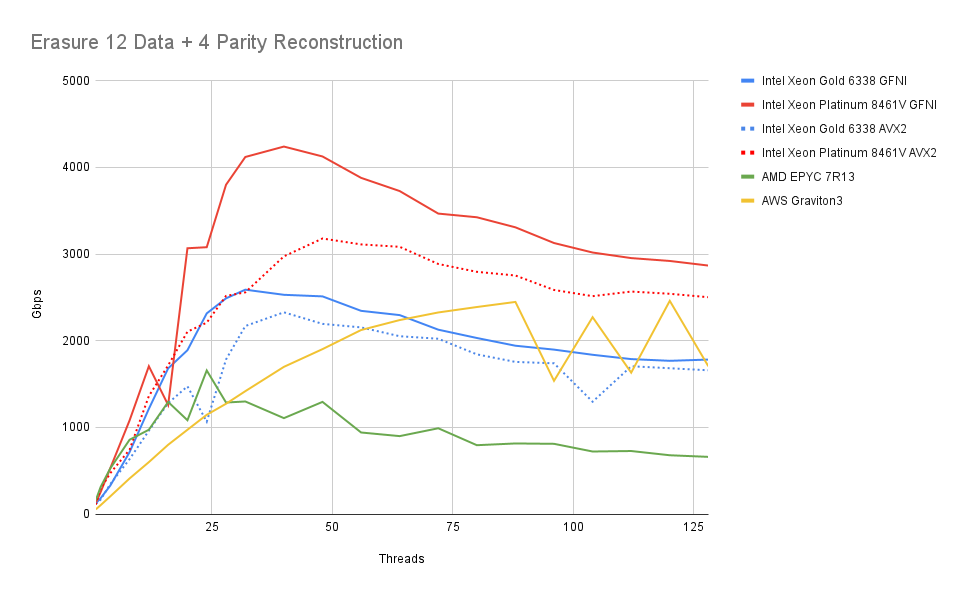
首先,我们观察到我们很快就超过了我们可以预期遇到的最大 NIC 速度。实际上,这意味着纠删码的 CPU 利用率在任何设置上都不会消耗超过几个内核。
我们还可以看到,随着使用的核心数量的增加,性能略有下降。这可能是内存带宽争用的结果。如上所述,由于其他系统瓶颈,任何服务器都不可能进入这个利用率范围。
8 个数据 + 8 个奇偶校验
我们研究的另一个设置是 16 个驱动器设置,每个对象被分为 8 个数据分片并创建 8 个奇偶校验分片。
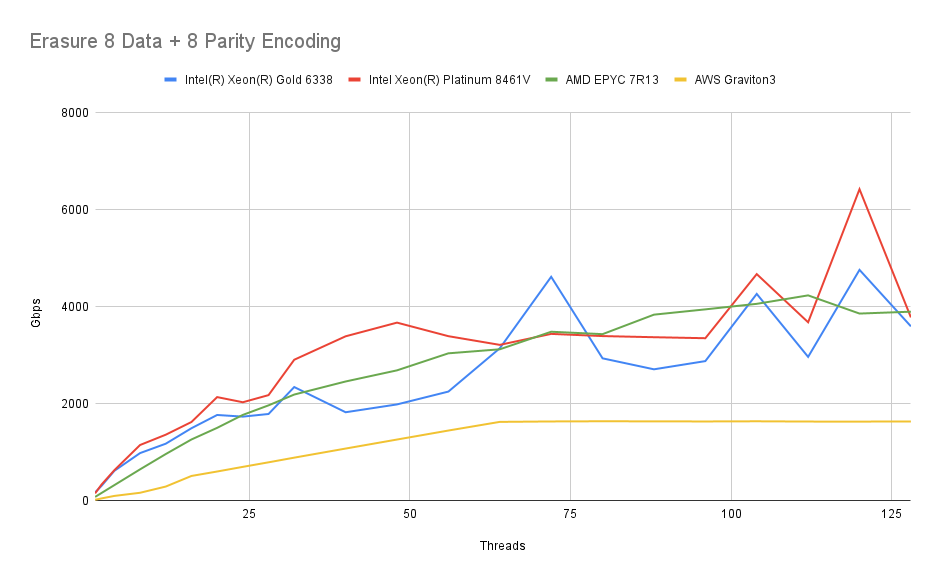
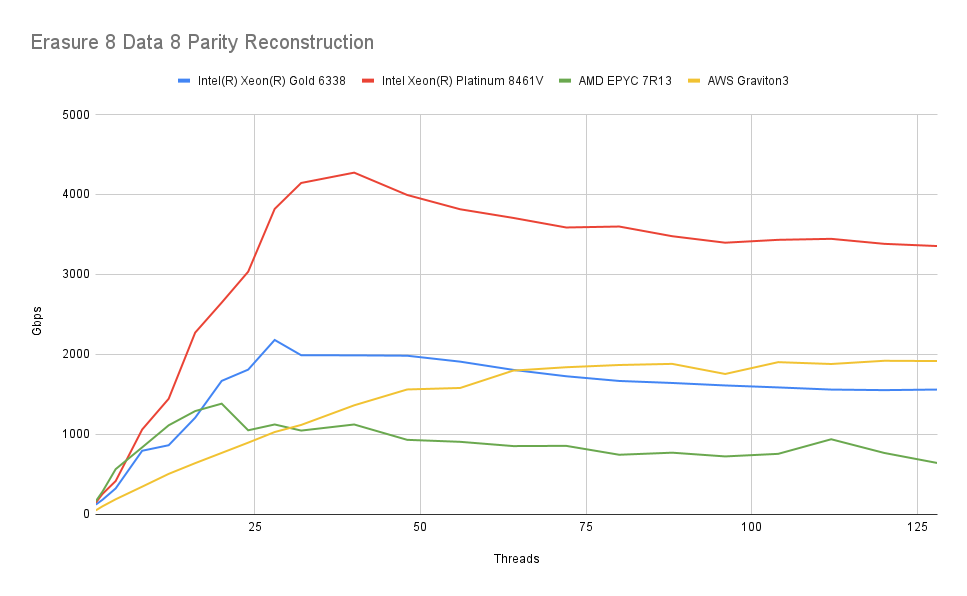
我们观察到类似的模式,但速度下降稍高。据推测,这是由于每次操作写入的数据量较多。但下降并不令人担忧,达到 400 GbE NIC 的速度应该不成问题。
4 个数据 + 4 个奇偶校验
最后,我们对一个设置进行基准测试,其中对象被分为 4 个数据分片和 4 个擦除分片:
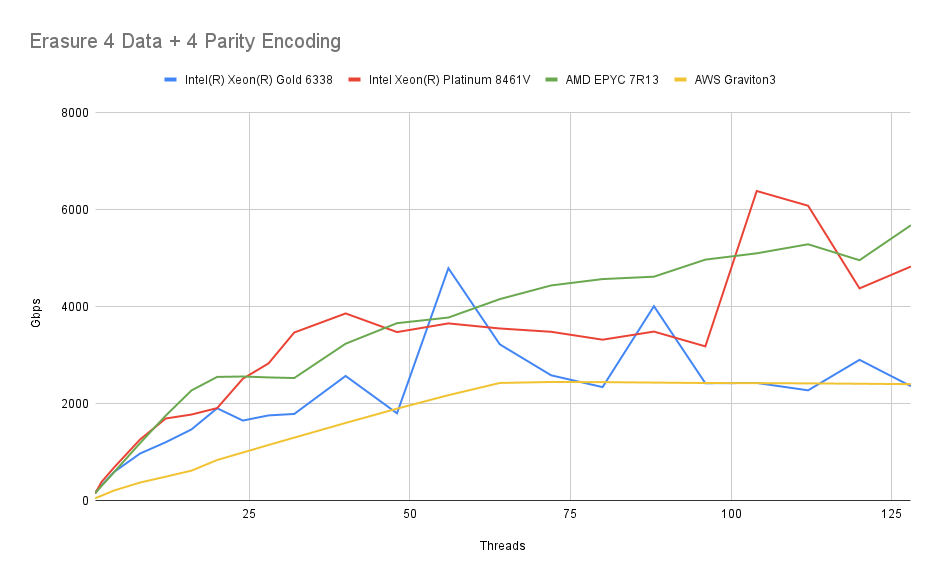
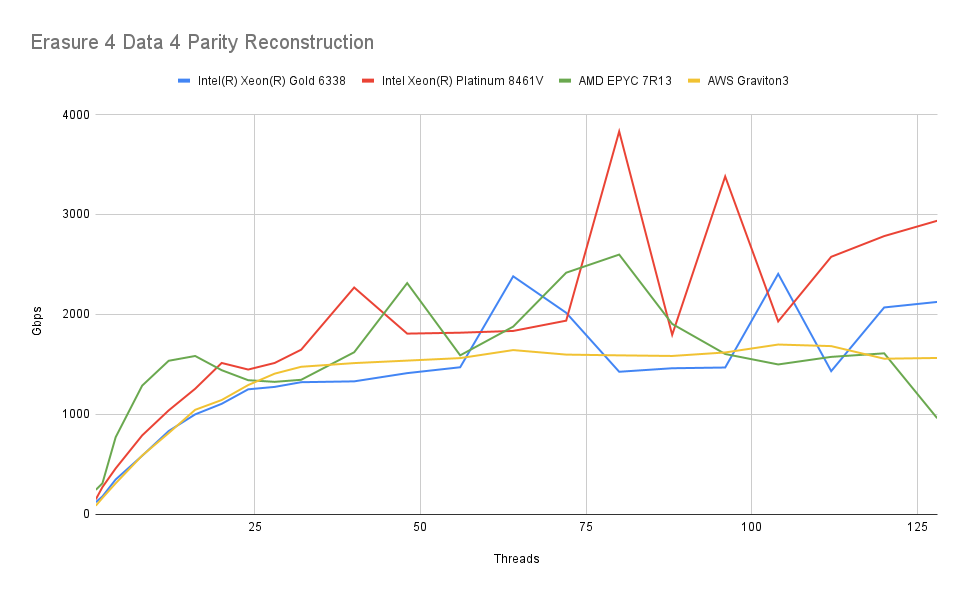
情况仍然相似。同样,读取和写入都不会为这些现代 CPU 带来显着的负载。
您可以在此处找到完整的测试结果。
分析与结论
通过此测试,我们希望确认商用硬件上的纠删码可以与专用硬件一样快 - 无需成本或锁定。我们很高兴地确认,即使以顶级 NIC 速度运行,我们也只会使用一小部分 CPU 资源在所有最流行的平台上进行纠删码。
这意味着 CPU 可以将其资源用于处理 IO 和请求的其他部分,并且我们可以合理地预期外部流处理器的任何处理都将至少占用同等数量的资源。
我们很高兴看到英特尔在其最新平台上提高了吞吐量。我们期待测试最新的 AMD 平台,并期望其 AVX512 和 GFNI 支持能够进一步提升性能。即使 Graviton 3 被证明有点落后,我们实际上并不认为它会成为一个重大瓶颈。