MLflow 模型注册表和 MinIO


MLflow 模型注册表允许您管理发往生产环境的模型。这篇文章从我上一篇文章关于 MLflow 跟踪的地方开始。在我的 Tracking 帖子中,我展示了如何记录参数、指标、工件和模型。如果你还没有读过它,那么有机会就读一读。在这篇文章中,我将展示如何注册和版本化记录的模型。作为额外的奖励,我还将展示如何将已注册的模型从 MLflow Model Registry 加载到内存中。MLflow 模型注册表是 MLflow 提供的众多功能之一,用于管理从模型创建到模型托管的所有方面。下面简要介绍了 MLflow 的高级功能。
- MLflow AI 网关 - AI 网关是一种工具,旨在简化组织内大型语言模型 ()LLM 提供程序的使用和管理。例如,OpenAI 和 Anthropic。它提供了一个高级接口,通过提供统一的终端节点来处理LLM请求,从而简化与这些LLMs接口的交互。
- MLflow 项目 - MLflow 项目是一种用于打包数据科学代码的格式,以便代码可重用且结果可重现。此外,Projects 还包括用于运行项目的 API 和命令行工具,使项目能够参与管道或工作流。
- MLflow 模型 - MLflow 模型是一种用于打包机器学习模型的标准格式,以便它们可以在各种下游工具中使用。
- MLflow 模型注册表 - 模型注册表允许在中央存储库中存储、注释、发现和管理模型。
- MLflow 配方 - MLflow 配方(以前称为 MLflow 管道)是一个基本框架,使数据科学家能够快速开发模型并将其部署到生产环境中。对于复杂的部署,请使用 MLflow Serving。
- MLflow 服务 - 服务模型可能很复杂。MLflow 通过提供简单的工具集将 ML 模型部署到各种目标(包括本地环境、云服务和 Kubernetes 集群)来简化模型服务。
- MLflow Tracing – 跟踪是一项功能,通过在执行模型托管服务期间捕获信息来增强LLM生成式 AI 应用程序中的可观测性。跟踪记录与请求的中间步骤相关的输入、输出和数据,从而可以纠正错误和意外行为。
- MLflow 跟踪 - MLflow 跟踪提供了一个 API,用于在训练模型时记录参数、代码版本、指标和输出文件。它还提供了一个用于可视化结果的 UI。
- MLflow 评估 - 评估允许自动测试模型的准确性、可靠性和效率,以便在开发阶段之外推广之前对其进行验证。Evaluation 提供了用于测试传统模型以及 LLMs的工具。
我假设您已经使用 PostgreSQL 和 MinIO 将 MLflow 作为远程服务器安装在开发计算机上。如果您尚未安装 MLflow,请查看我关于使用 MLflow 和 MinIO 设置开发计算机的博文,其中我展示了如何使用 Docker Compose 运行如下所示的服务。

在此部署中,MinIO 用于存储模型和数据集。如果您正在试验模型并最终将它们移动到生产环境中,那么为这些工件提供高质量的对象存储非常重要。如果您正在训练大型语言模型,则尤其如此。
什么是注册模型?
已注册的模型是生产环境的候选项。您应该在实验中注册性能最佳的模型。注册模型后,您可以添加元数据,例如标签和描述。也可以在 Registry 中对模型进行版本控制;每个版本都有自己的描述和标签。在旧版本的 MLflow 中,可以指定模型的阶段以跟踪其状态。允许的阶段包括 None、Stage、Production 和 Archive。在本文中,我将展示如何使用最新版本的 MLflow 注册模型,在撰写本文时为 2.20.3。本文中显示的所有代码都可以在这里找到。要注册模型,您必须之前使用我在跟踪帖子中演示的 log_model() 函数记录它。回想一下这篇文章,我使用了 log_model() 函数的简单风格将模型保存到 MLflow。这行代码如下所示。
# Log the trained model.
model_artifact_path = 'mnistmodel'
mlflow.pytorch.log_model(model, artifact_path=model_artifact_path)
要利用 Model Registry 的所有功能,我们需要通过添加签名来升级此命令。签名是模型的架构。它告诉 MLflow 允许进行推理的数据类型。从下面修改后的日志记录代码中可以看到,MLflow 提供了一个 infer_signature() 函数,顾名思义,该函数根据您从训练集或测试集发送的几个样本来推断模型的签名。
# Log the trained model.
images, labels = next(iter(test_loader))
img = images[0].view(1, 784)
label = labels[0]
print(img.size())
print(label.size())
with torch.no_grad():
logps = model(img)
model_signature = mlflow.models.infer_signature(img.numpy(), logps.numpy())
model_artifact_path = 'mnistmodel'
mlflow.pytorch.log_model(model, artifact_path=model_artifact_path,
signature=model_signature)
一但一个模型被记录下来并有一个 schema,我们就可以注册它。有两种方法可以注册模型。一种方法是使用 MLflow API。另一种方法是使用 MLflow UI 查找和注册以前记录的模型。我将展示这两种技术。让我们从用于注册的 API 开始。
使用 API 注册模型
使用 API 注册以前记录的模型的最佳方法如下所示。我稍后将简要介绍另外两种技术 - 但下面的技术是最好的,因为它允许您使用两个单独的 API 调用创建顶级集合实体和模型的新版本。这使您可以灵活地为每个 Cookie 提供不同的描述和不同的标签。将顶级集合实体视为一个对象,它维护具有相同名称的模型的所有版本的列表。
model_name = 'mnist_nn_model'
client = MlflowClient()
# Register top-level collection entity if it has not been previously registered.
filter_string = f"name='{model_name}'"
results = client.search_registered_models(filter_string=filter_string)
if len(results) == 0:
model_tags = {'framework': 'Pytorch'}
model_description = 'Various versions of the MNIST model with different hidden layers.'
client.create_registered_model(model_name, model_tags, model_description)
# Register the new version
run_id = active_run.info.run_id
run_uri = f'runs:/{run_id}/{model_artifact_path}'
model_source = RunsArtifactRepository.get_underlying_uri(run_uri)
version_tags = {'layers': len(params['hidden_sizes'])}
version_description = f'Hidden sizes: {params["hidden_sizes"]}'
model_version = client.create_model_version(model_name, model_source, run_id,
tags=version_tags,
description=version_description)
create_registered_model() 函数创建集合实体。注意 - 只有当集合不存在时,才能调用它 - 否则,它会引发错误。在上面的代码中,我使用了 search_registered_models() 函数来确保如果模型存在,则此函数永远不会被调用。create_model_version() 函数创建模型的新版本。请注意,在上面的代码中,集合和版本具有不同的描述和标记。
注册模型的多个版本后,您将能够在 UI 中查看它们。让我们看看 MLflow UI 中的模型注册表。通过导航到 http://localhost:5000/ 启动 UI。默认视图将显示您的所有实验。我们想要查看已注册的模型,因此在页面顶部找到 Models 选项卡并单击它。您将看到已注册的所有模型的列表。示例如下所示。

此视图显示所有已注册的模型。对于每个模型,将显示最新版本。单击模型名称将显示下面的页面。

在这里,我们看到了这个模型的所有版本。此处显示的描述和标记适用于顶级条目。因此,它们应该适用于所有版本。最后,MLflow 文档还介绍了可用于注册模型的另外两组 API。首先,专门为每个框架开发的日志记录 API 具有注册功能。(这些函数位于 Sklearn 的 mlflow.sklearn 和 Pytorch 的 mlflow.pytorch 下。它们不能为您提供与我上面展示的相同级别的控制,并且支持因框架而异。其次,还有一个 mlflow.register_model() 函数。此函数不允许您控制集合实体的创建方式,并且没有 description 参数。
使用 MLflow UI 注册模型
事实证明,您不需要 API 来注册模型。可以使用 MLflow UI 注册以前记录的模型。如果您希望人工确定应将哪个记录的模型提升到 Registry,这可能是注册模型的首选方法。让我们再浏览一下 UI,看看这是如何完成的。首先导航到 Experiements 选项卡,然后选择包含要注册的模型的实验。
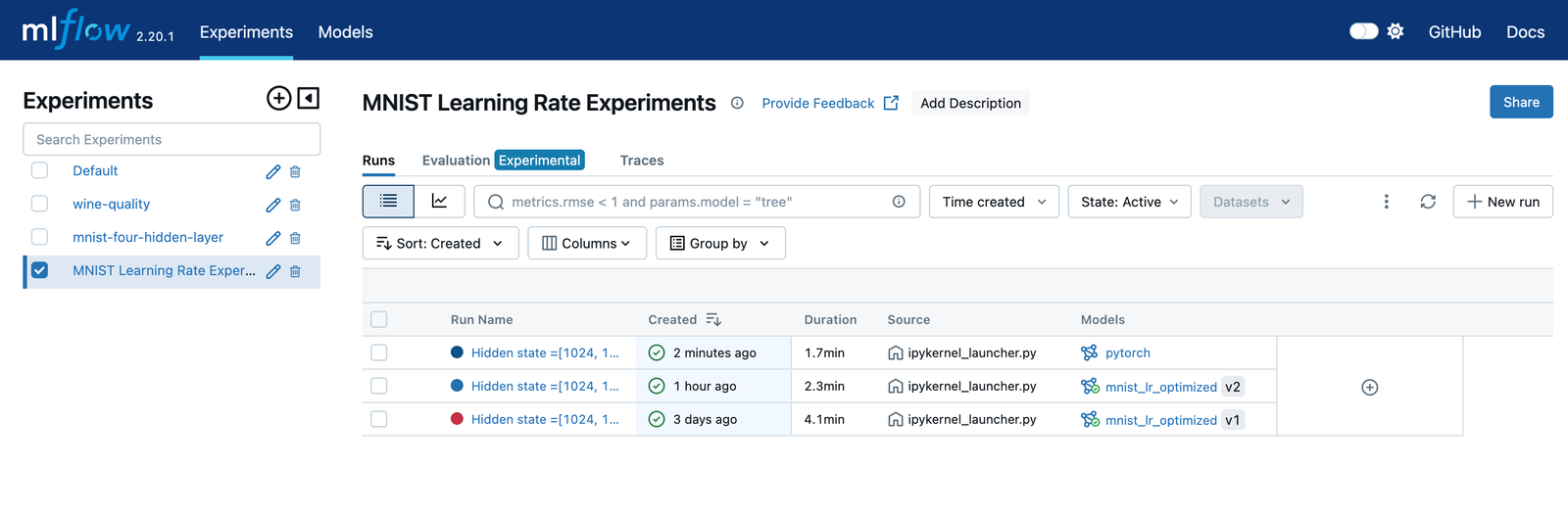
如果将 “Model” 添加到为每次运行显示的列列表中,则可以看到哪些运行已记录模型,哪些运行已注册。在上面的屏幕截图中,已注册的模型具有名称和版本名称。选择包含您希望位于模型注册表中的未注册模型的运行。这将带您进入如下所示的运行详细信息页面。请注意,当您在此页面的 artifacts 部分中选择模型时,将显示 Register Model (注册模型) 按钮。
单击 'Register Model' 按钮将显示下面的对话框。

如果需要新的集合实体,我们将在此处创建顶级集合实体,或者我们可以将模型添加到已注册模型的现有集合中。完成此对话框后,您的模型将被注册。导航到 Models 选项卡并找到新注册的模型。单击您的模型可查看此模型的版本列表。如下所示。另请注意,集合级别有描述和标记。

单击特定版本,我们可以查看其详细信息。

该版本有自己的描述和标签。您可以使用此页面编辑这些值,还可以设置模型的阶段。此外,请查看此模型的架构。当我们加载模型并对其执行测试时,这将发挥作用,我们将在下一节中执行此作。
加载和测试已注册的模型
我们要做的最后一件事是加载以前注册的模型。毕竟,如果您无法检索模型并执行进一步的实验,那么记录和注册模型又有什么用呢?我将在本节中展示的内容不应与所谓的 Model Serving 相混淆。当您提供模型时,您可以采用以前经过训练和测试的模型,并将其与其所有依赖项一起部署,以便它可以作为独立服务执行推理。我们在这里要做的只是检索以前注册的模型。要使用此模型,您必须自己处理所有依赖项。如果模型仍在开发中,并且您想要查看同事刚刚训练的模型的新版本,这将非常有用。也许在训练模型时测试集不可用,并且您想查看新模型对从未见过的数据的性能。
下面的代码会将以前注册的模型加载到内存中。
model_name = 'mnist_nn_model'
model_version = 6
mlflow.set_tracking_uri('http://localhost:5000/')
model = mlflow.pyfunc.load_model(model_uri=f"models:/{model_name}/{model_version}")
type(model)
您只需知道型号名称和版本号。这些值将用于创建模型 URI,该 URI 将传递给 mlflow.pyfunc.load_model() 函数。在 notebook 中运行时,上述代码将生成以下输出。
mlflow.pyfunc.PyFuncModel
上面代码中的类型检查告诉我们,该模型是 mlflow.pyfunc.PyFuncModel 的实例。MLflow 使用 PyFuncModel 类包装所有模型。这似乎没有必要,但请记住,MLflow 是适用于所有框架的工具。因此,如果您所在的团队正在试验 Pytorch、TensorFlow 和 Sklearn 等多个框架,那么相同的下游测试或推理代码将适用于所有模型,因为它们被包装在一个通用类中。
我们的包装模型有一个 predict() 函数,用于推理。让我们创建一个使用此模型的测试函数。
def test_model(model: mlflow.pyfunc.PyFuncModel, loader: DataLoader) -> Dict[str, Any]:
correct_count, total_count = 0, 0
for images, labels in loader:
for i in range(len(labels)):
img = images[i].view(1, 784)
# Turn off gradients to speed up this part
with torch.no_grad():
logps = model.predict(img.numpy())
# Output of the network are log-probabilities,
#need to take exponential for probabilities
ps = np.exp(logps)
probab = list(ps[0])
pred_label = probab.index(max(probab))
true_label = labels.numpy()[i]
if(true_label == pred_label):
correct_count += 1
total_count += 1
testing_metrics = {
'incorrect_count': total_count-correct_count,
'correct_count': correct_count,
'accuracy': (correct_count/total_count)
}
print("Number Of Images Tested =", total_count)
print("\nModel Accuracy =", (correct_count/total_count))
return testing_metrics
要使上述函数正常工作,我们需要一个测试集。下面的代码将为我们提供 MNIST 数据集的测试集。
def load_test_images(batch_size: int) -> Tuple[Any]:
# Define a transform to normalize the data
transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))])
# Download and load the testing data
test_dataset = datasets.MNIST('./mnistdata', download=True, train=False,
transform=transform)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=True)
return test_loader
这就是从 Model Registry 加载已注册模型并进一步试验它所需的一切。请注意,如果包装模型的 predict() 方法向您抛出错误,那么您推断的 schema 很可能是错误的。在这种情况下,请返回记录模型的代码,并确保 infer_schema 函数中使用的数据类型和形状与包装模型的 predict() 方法接收的数据类型和形状相同。
总结
将 MLflow 和 MinIO 相结合可提供强大的协同作用,从而提升机器学习开发过程。MLflow 简化的实验跟踪、模型版本控制和部署功能可确保数据科学家和工程师之间的高效协作和可重复性。通过集成 MinIO 的高性能对象存储,该过程获得了可扩展性、成本效益和强大的数据管理,从而促进了大规模数据集和模型的无缝存储和共享。这种统一的方法可以提高团队的工作效率,加速创新,并为自信地构建高级机器学习应用程序奠定坚实的基础。