数据湖屋的颠覆性本质


介绍
1997 年,克莱顿·克里斯滕森 (Clayton Christensen) 在他的《创新者的困境》一书中确定了一种创新模式,该模式可跟踪现有企业和新进入者之间按细分市场划分的能力、成本和采用情况。 他将这种模式称为“颠覆性创新”。 并非每一个成功的产品都具有颠覆性——即使它会导致成熟的企业失去市场份额,甚至完全失败。 “颠覆性创新”这个标签有一个非常精确的定义。 它是按细分市场(低端、主流和高端)划分的客户需求、现有企业的能力和进入者的能力之间随时间的关系。 产品功能和客户需求之间关系的可视化如下所示。
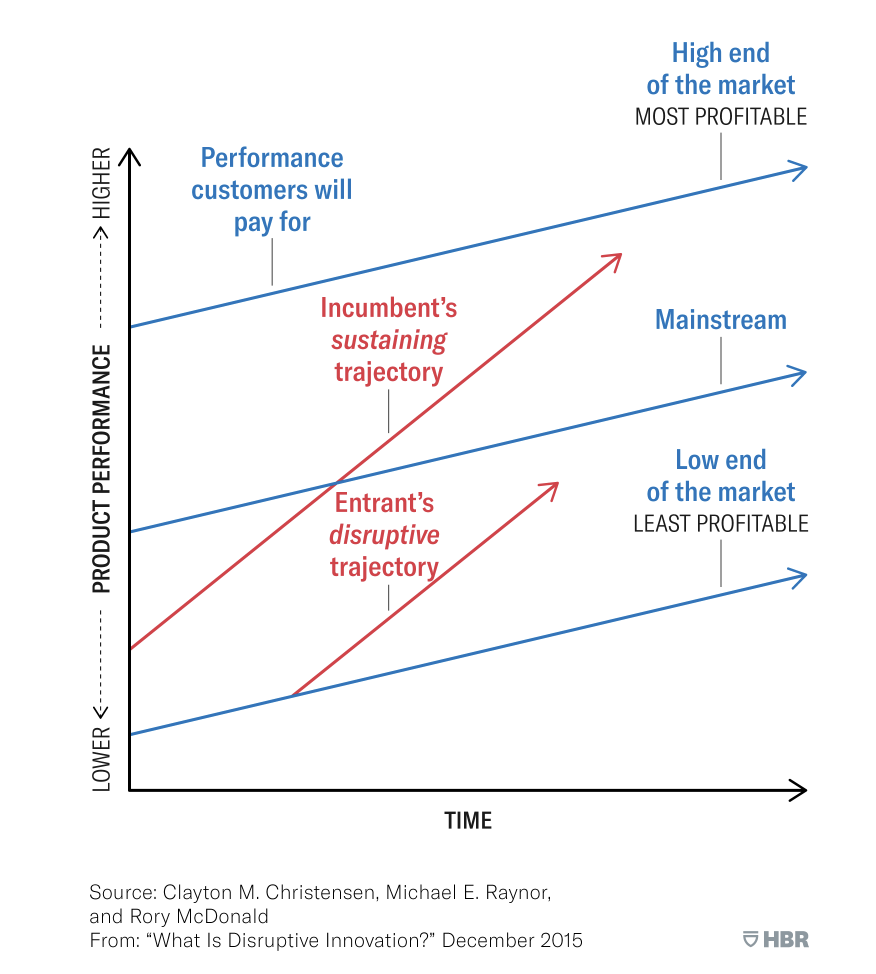
Source: 什么是颠覆性创新?
颠覆理论的简要概述如下:
- 颠覆性创新是一个随着时间的推移而发生的过程。
- 当低端市场被忽视时,颠覆的条件就完美了。
- 当进入者利用服务不足的低端市场获得立足点时,颠覆就开始了。
- 进入者必须不断创新才能进入更高的市场。
- 如果进入者达到市场高端并能够保持成本效益的能力,现有企业可能会遇到麻烦。
识别新技术是否属于这种模式的承诺是,您可以识别挑战者和现任者。 简而言之,您可以预测采用情况 - 新技术将如何发展。 您还可以确定随着现有产品失去市场份额,谁将被取代。 此外,作为软件行业的消费者或从业者,理解变化确实是这个行业的圣杯——变化是唯一不变的行业。 无论您是寻找下一只热门股票的投资者、试图让您的公司保持最新状态的决策者,还是试图让您的技能保持最新的技术专家 - 能够洞察周围的情况都是非常宝贵的。
快进到今天 - 2023 年 9 月,有一批初创公司正在偷偷摸摸地构建所谓的“数据湖屋”。 Data Lakehouse 不是某个公司的单一产品。 相反,它是一种设计模式。 此设计模式利用 Uber、Netflix 和 Databricks 等公司的开放规范。 它还使用 MinIO、Apache Spark 和 Project Nessie 等公司和组织的开源技术,在数据目录级别实现类似 Git 的语义。
本文的目的是探讨颠覆性创新的定义,了解数据湖屋到底是什么以及它如何在行业中被采用。 一旦理解了这两个想法,我们就可以得出数据湖屋是否具有颠覆性以及是否会遵循许多其他颠覆性技术所遵循的模式的结论。
让我们看看数据仓库和数据湖屋发生了什么。
能力比较
让我们定义并比较组织在决定将用于商业智能、数据分析和机器学习的数据存放在何处时可用的所有选项。 从较高的层面来看,这些存储选项是数据湖、数据仓库和数据湖屋。
数据仓库
数据仓库旨在存储和管理来自各种来源的大量结构化数据。 它们将数据组织到表中,并且通常通过向单个服务器或节点添加更多资源来垂直扩展。 (一些现代数据仓库在某种程度上也支持水平扩展。)这些表需要预定义的模式,这可能会限制处理不断变化的或非结构化数据时的灵活性。 数据仓库支持时间旅行,该功能允许以过去存在的方式查看表。 但是,数据仓库不支持数据版本控制,这允许表像代码存储库一样进行分支。 由于需要高性能硬件和软件许可证,运行数据仓库的成本可能会很高,尤其是对于大规模操作。
数据湖
数据湖旨在存储大量保持原始、本机格式的非结构化数据。 由于数据以其原始格式存储,因此不需要预定义的模式。 因此,它们更加灵活,可以处理更广泛的数据类型。 由于它们不支持表的概念 - 不支持时间旅行和数据版本控制。 数据湖具有成本效益,因为它们利用低成本的存储解决方案并水平扩展以适应不断增长的数据量。
数据湖屋
数据湖屋旨在通过根据数据的使用方式提供两种存储技术来处理结构化和非结构化数据。 它们支持结构化数据的模式演化,允许数据工程师和分析师根据需要对模式进行更改,而不需要大量的 ETL 过程。 这种灵活性在数据快速变化的时代至关重要。 它们还支持时间旅行和数据版本控制。 Data Lakehouse 基于开源和云原生技术构建,在工具选择和集成方面提供了更大的灵活性。 最后,它们更具成本效益,因为它们利用对象存储和分布式计算,允许存储和处理引擎水平扩展以适应不断增长的数据量并提高查询性能。 虽然数据湖屋为即席查询和探索性查询提供了良好的性能,但它们可能无法与数据仓库执行复杂的结构化数据分析任务的性能相匹配。
把它们放在一起
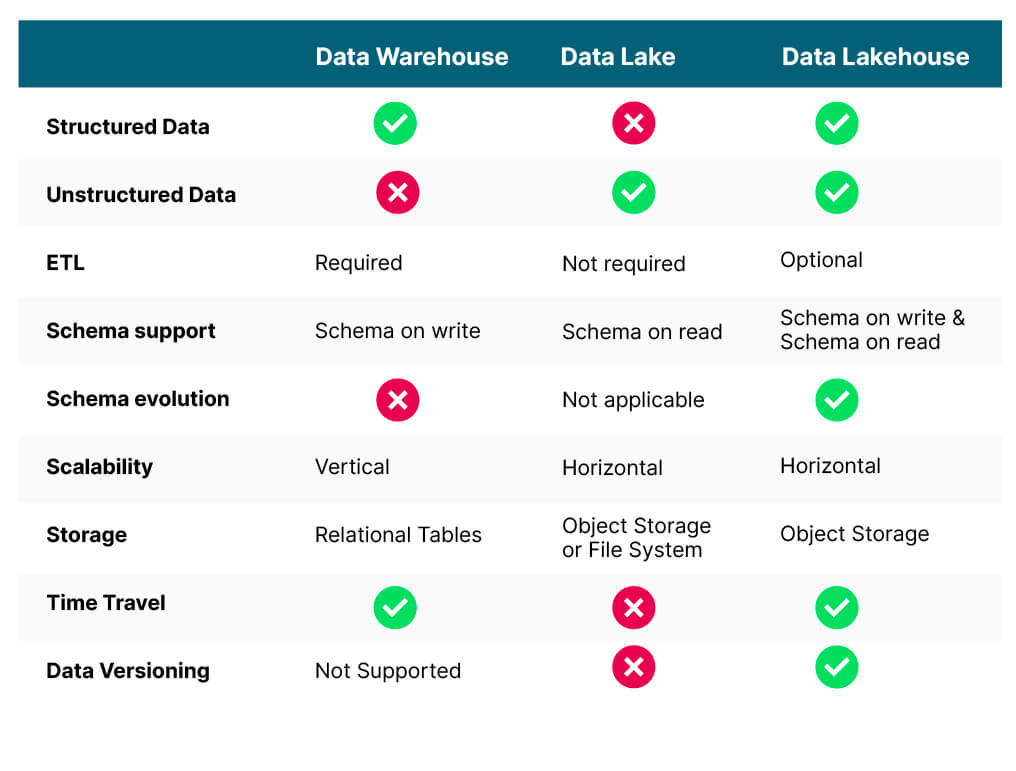
数据湖屋的承诺是,它们将把数据仓库和数据湖的最佳特性和功能结合到一个解决方案中。 这似乎好得令人难以置信,但开放表格式 (OTF) 的最新进展使得将对象存储用于结构化数据和非结构化数据成为可能。 Apache Iceberg、Hudi 和 Delta Lake 是当今三种流行的 OTF。 它们是规范,一旦实现,就会为处理引擎提供有效查询对象存储中的数据所需的元数据 - 这是数据湖屋的数据仓库组件。 由于正在使用对象存储,因此可以将相同的对象存储用于非结构化数据 - 这是 Data Lakehouse 的 Data Lake 端。 下图显示了 Data Lakehouse 的组件。
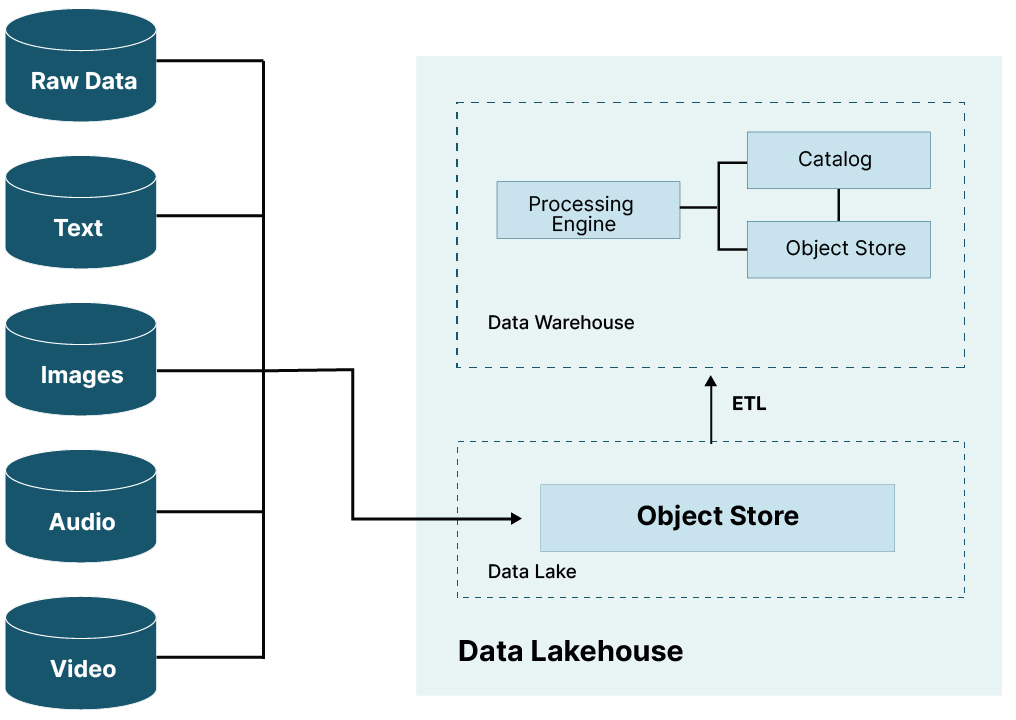
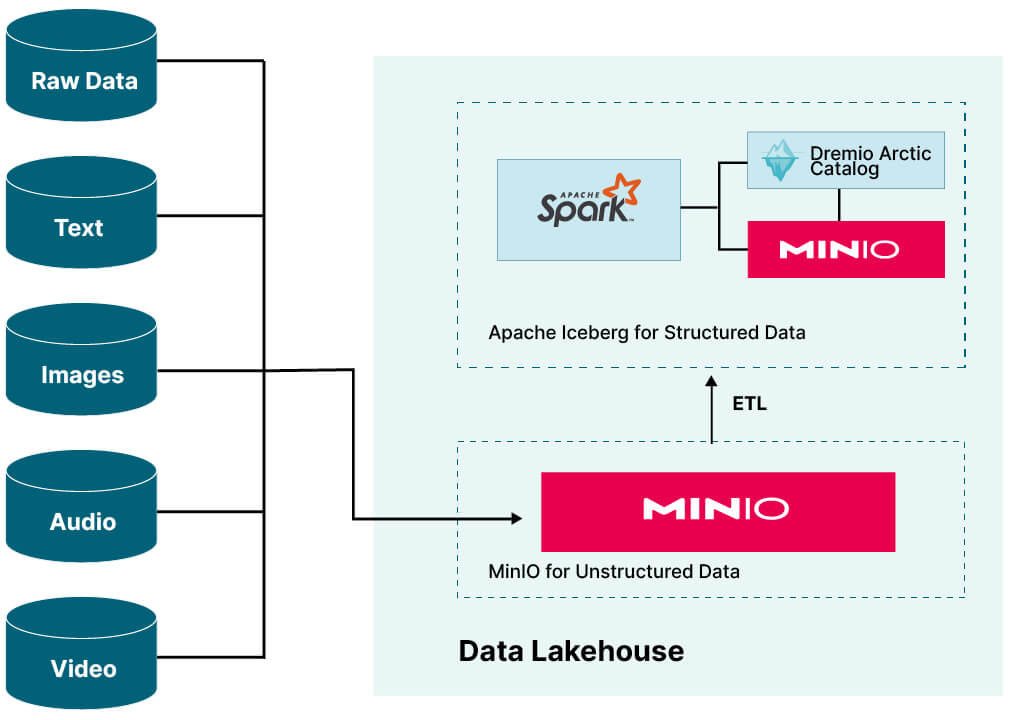
Data Lakehouse 不是某个公司的单一产品。 参考上图,我们可以看到它是来自各个供应商的产品的集合。 您需要一个对象存储、一个处理引擎和一个目录。 此外,没有任何一家供应商拥有这三个组件中任何一个的排他性。 该设计是分解的,分解提供了允许您使用可能已有的选项。 下面显示了具体 Data Lakehouse 实现的示例。 如果您已经将 MinIO 用于对象存储,请将其用于您的 Data Lakehouse。 已经在 Spark 上实现计算标准化,那么它就可以成为您的处理引擎。 最后,如果您对数据版本控制感兴趣,请考虑使用 Dremio Arctic 的目录。
湖屋有破坏性吗?
现在,我们可以回到颠覆理论的最初原则,看看数据湖屋的采用是否会以颠覆数据仓库的方式进行。
我认为低端市场没有上一节中描述的功能。 然而,业界普遍认为专有数据仓库价格昂贵。 此外,许多组织正在寻求削减云计算成本 - 这项努力将从数据开始。 与此同时,许多组织拥有臃肿的本地数据库,这些数据库本质上是数据仓库,需要重新构建平台。 最后,人工智能的繁荣增加了对非结构化数据的需求。 这三种力量——成本削减、平台重组以及对支持大型语言模型的非结构化数据的需求增加,为数据湖屋提供了开始颠覆性过程所需的立足点。
Data Warehouse 供应商和 Data Lakehouse 供应商都在不断提高自己的能力。 数据仓库供应商及其产品被认为更加成熟,当今的大型组织更愿意使用它们。 然而,数据仓库的单服务器扩展设计令人担忧。 这不是一个现代的解决方案 - 组织将不得不支付能够处理其高峰工作负载并在低使用率期间消耗现金的服务器的费用。 这代表了数据湖屋的攻击媒介。 Data Lakehouse 的所有组件都可以在可横向扩展的集群中的低成本服务器上运行。 此外,Data Lakehouse 的计算部分可以弹性扩展,在低使用率期间节省资金。
此外,仅存在于云中的产品也有局限性。 他们可能会成为成本削减的受害者,或者如果数据不能驻留在云端,他们可能根本不会被考虑。 数据湖屋在这方面也有优势。 它们的现代设计是云原生的,可以在微服务集群可以运行的任何地方运行。
概括
数据湖屋颠覆数据仓库的一切都已经准备就绪,尤其是仅存在于云中的昂贵数据仓库。 成本削减、平台重构和大型语言模型的需求为 Data Lakehouse 提供了立足点。 与数据仓库过时的设计相比,它们的现代设计将为它们提供一旦进入高端市场就取得成功所需的竞争优势。 此外,他们还得到初创公司和开源社区的支持。